Notebook for scDoRI model training and downstream analysis
[1]:
import logging
import torch
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
from scdori import config
from scdori.data_io import load_scdori_inputs, save_model_weights
from scdori.utils import set_seed
from scdori.models import scDoRI
from scdori.train_scdori import train_scdori_phases
from scdori.train_grn import train_model_grn
from scdori.models import initialize_scdori_parameters
from pathlib import Path
logger = logging.getLogger(__name__)
[2]:
from importlib import reload
import sys
for module_name in list(sys.modules.keys()):
if module_name.startswith("scdori"):
reload(sys.modules[module_name])
Loading and preparing data for training and model initialisation#
[3]:
logging.basicConfig(level=config.logging_level)
logger.info("Starting scDoRI pipeline with integrated GRN.")
set_seed(config.random_seed)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
logger.info(f"Using device: {device}")
INFO:__main__:Starting scDoRI pipeline with integrated GRN.
INFO:scdori.utils:Random seed set to 200.
INFO:__main__:Using device: cuda:0
1. load data#
uses the path specified in config file to load processed RNA and ATAC anndata as well as precomputed insilico-chipseq matrix and peak-gene distances
[ ]:
rna_metacell, atac_metacell, gene_peak_dist, insilico_act, insilico_rep = load_scdori_inputs(config)
gene_peak_fixed = gene_peak_dist.clone()
gene_peak_fixed[gene_peak_fixed >0]=1 # mask for peak-gene links based on distance
INFO:scdori.data_io:Loading RNA from /data/saraswat/new_metacells/data_gastrulation_single_cell/generated/rna_processed.h5ad
INFO:scdori.data_io:Loading ATAC from /data/saraswat/new_metacells/data_gastrulation_single_cell/generated/atac_processed.h5ad
INFO:scdori.data_io:Loading gene-peak dist from /data/saraswat/new_metacells/data_gastrulation_single_cell/generated/gene_peak_distance_exp.npy
INFO:scdori.data_io:Loading insilico embeddings from /data/saraswat/new_metacells/data_gastrulation_single_cell/generated/insilico_chipseq_act.npy & /data/saraswat/new_metacells/data_gastrulation_single_cell/generated/insilico_chipseq_rep.npy
2. computing indices of genes which are TFs and setting number of cells per metacell ( set to 1 for single cell data)#
[5]:
# computing indices of genes which are TFs and setting number of cells per metacell ( set to 1 for single cell data)
rna_metacell.obs['num_cells']=1
rna_metacell.var['index_int'] = range(rna_metacell.shape[1])
tf_indices = rna_metacell.var[rna_metacell.var.gene_type=='TF'].index_int.values
num_cells = rna_metacell.obs.num_cells.values.reshape((-1,1))
3. onehot encoding the batch column for entire dataset#
[ ]:
batch_col = config.batch_col
rna_metacell.obs['batch'] = rna_metacell.obs[batch_col].values
atac_metacell.obs['batch'] = atac_metacell.obs[batch_col].values
# obtaining onehot encoding for technical batch,
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
enc.fit(rna_metacell.obs['batch'].values.reshape(-1, 1) )
onehot_batch = enc.transform(rna_metacell.obs['batch'].values.reshape(-1, 1)).toarray()
enc.categories_
[array(['E7.5_rep1', 'E7.5_rep2', 'E7.75_rep1', 'E8.0_rep1', 'E8.0_rep2',
'E8.5_CRISPR_T_KO', 'E8.5_CRISPR_T_WT', 'E8.5_rep1', 'E8.5_rep2',
'E8.75_rep1', 'E8.75_rep2'], dtype=object)]
4. making train and evaluation datasets#
[7]:
# 2) Make small train/test sets
n_cells = rna_metacell.n_obs
indices = np.arange(n_cells)
train_idx, eval_idx = train_test_split(indices, test_size=0.2, random_state=42)
train_dataset = TensorDataset(torch.from_numpy(train_idx))
train_loader = DataLoader(train_dataset, batch_size=config.batch_size_cell, shuffle=True)
eval_dataset = TensorDataset(torch.from_numpy(eval_idx))
eval_loader = DataLoader(eval_dataset, batch_size=config.batch_size_cell, shuffle=False)
5. Build scDoRI model using parameters from config file#
[ ]:
num_genes = rna_metacell.n_vars
num_peaks = atac_metacell.n_vars
num_tfs = insilico_act.shape[1]
num_batches = onehot_batch.shape[1]
from scdori.models import scDoRI
model = scDoRI(
device=device,
num_genes=num_genes,
num_peaks=num_peaks,
num_tfs=num_tfs,
num_topics=config.num_topics,
num_batches=num_batches,
dim_encoder1=config.dim_encoder1,
dim_encoder2=config.dim_encoder2
).to(device)
6. initialising scDoRI model with precomputed matrices and setting gradients#
initialising with precomputed insilico-chipseq matrices and distance dependent peak-gene links
also setting corresponding gradients for TF-gene links to False as they are not updated in Phase 1 of training
[ ]:
initialize_scdori_parameters(
model,
gene_peak_dist.to(device), gene_peak_fixed.to(device),
insilico_act=insilico_act.to(device),
insilico_rep=insilico_rep.to(device),phase="warmup")
scDoRI parameters (peak-gene distance & TF binding) initialized and relevant parameters frozen.
Train Phase 1 of scDoRI model#
here topics are inferred using reconstruction of ATAC peaks (module 1), reconstruction of RNA from predicted ATAC (module 2) and reconstruction of TF expression (module 3)
Warmup start is used where only module 1 and module 3 are trained for some initial epochs before adding module 2
[ ]:
model = train_scdori_phases(model, device, train_loader, eval_loader,rna_metacell, atac_metacell,num_cells, tf_indices, onehot_batch,config)
[ ]:
# saving the model weight correspoinding to final epoch where model stopped training
save_model_weights(model, Path(config.weights_folder_scdori), "scdori_final")
Train Phase 2 of scDoRI model#
here activator and repressor TF-gene links per topic are inferred (module 4)
optionally the encoder and other model parameters from module 1,2,3 are frozen for stability
7. Load best checkpoint from Phase 1#
[ ]:
# Phase 2
# loading the best checkpoint from Phase 1
from scdori.downstream import load_best_model
model = load_best_model(model, Path(config.weights_folder_scdori) / "best_scdori_best_eval.pth", device)
8. Set gradients for Phase 2 training#
TF-gene links are learnt in this step
[ ]:
initialize_scdori_parameters(
model,
gene_peak_dist, gene_peak_fixed,
insilico_act=insilico_act,
insilico_rep=insilico_rep,phase="grn")
9. Phase 2 training and saving model weights#
[ ]:
# train Phase 2 of scDoRI model, TF-gene links are learnt in this phase and used to reconstruct gene-expression profiles
model = train_model_grn(model, device, train_loader, eval_loader,rna_metacell, atac_metacell,num_cells, tf_indices, onehot_batch,config)
[ ]:
# saving the model weight correspoinding to final epoch where model stopped training
save_model_weights(model, Path(config.weights_folder_grn), "scdori_final")
Downstream analysis#
scDoRI supports a comprehensive suite of downstream analyses for single-cell multiome RNA-ATAC data. These include dimensionality reduction using latent topics, identification of gene and peak programs associated with each topic, inference of enhancer–gene interactions, and construction of topic-specific transcription factor–gene regulatory networks (GRNs).
We demonstrate these capabilities using the mouse gastrulation dataset from https://www.biorxiv.org/content/10.1101/2022.06.15.496239v1
[226]:
from scdori.downstream import (
load_best_model,
compute_neighbors_umap,
compute_topic_peak_umap,compute_topic_gene_matrix,
compute_atac_grn_activator_with_significance,
compute_atac_grn_repressor_with_significance,
compute_significant_grn,
visualize_downstream_targets,
plot_topic_activation_heatmap,
get_top_activators_per_topic,
get_top_repressor_per_topic,
compute_activator_tf_activity_per_cell,
compute_repressor_tf_activity_per_cell,save_regulons
)
from scdori.evaluation import get_latent_topics
import scanpy as sc
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import scipy
from scdori.train_grn import get_tf_expression
[227]:
from importlib import reload
import sys
for module_name in list(sys.modules.keys()):
if module_name.startswith("scdori"):
reload(sys.modules[module_name])
10. Load best checkpoint model#
[11]:
model = load_best_model(model, Path(config.weights_folder_grn) / "best_scdori_best_eval.pth", device)
INFO:scdori.downstream:Loaded best model weights from weights_directory_grn/best_scdori_best_eval.pth
11. Computing and visualising latent topic activity per cell#
[12]:
# creating dataloader for all cells
n_cells = rna_metacell.n_obs
indices = np.arange(n_cells)
all_dataset = TensorDataset(torch.from_numpy(indices))
all_dataset_loader = DataLoader(all_dataset, batch_size=config.batch_size_cell_prediction, shuffle=False)
[13]:
# get scDoRI latent embedding (topics)
scdori_latent = get_latent_topics(model, device, all_dataset_loader,rna_metacell,atac_metacell,num_cells,tf_indices,onehot_batch)
Extracting latent topics: 100%|██████████| 112/112 [01:26<00:00, 1.29it/s]
[14]:
# adding scDoRI embedding to the anndata object
rna_metacell.obsm['X_scdori'] = scdori_latent
[15]:
## adding color palette
colPalette_celltypes = ['#532C8A', '#c19f70', '#f9decf','#c9a997', '#B51D8D', '#3F84AA', '#9e6762', '#354E23', '#F397C0',
'#ff891c', '#635547', '#C72228', '#f79083', '#EF4E22', '#989898', '#7F6874', '#8870ad', '#647a4f',
'#EF5A9D', '#FBBE92', '#139992', '#cc7818', '#DFCDE4', '#8EC792', '#C594BF', '#C3C388', '#0F4A9C', '#FACB12', '#8DB5CE', '#1A1A1A',
'#C9EBFB', '#DABE99', '#65A83E', '#005579', '#CDE088', '#f7f79e', '#F6BFCB']
cell_type_sorted = sorted(list(set(rna_metacell.obs['celltype'].values)))
color_dict = dict(zip(cell_type_sorted,colPalette_celltypes))
col_sorted = []
for i in sorted(cell_type_sorted):
col_sorted.append(color_dict[i])
rna_metacell.uns['celltype_colors']= col_sorted
#rna_metacell.uns['celltype_plot_colors']= col_sorted
#rna_ad_tl.uns['celltype_colors']= col_sorted
[16]:
# computing neighbourhood graph and UMAP based on scDoRI embedding, UMAP parameters can be set in config file
compute_neighbors_umap(rna_metacell, rep_key="X_scdori")
INFO:scdori.downstream:=== Computing neighbors + UMAP on scDoRI latent ===
INFO:scdori.downstream:Done. UMAP stored in rna_anndata.obsm['X_umap'].
[17]:
# visualing cell-types on scDoRI computed UMAP
sns.set(font_scale = 0.3)
sns.set_style("whitegrid")
with plt.rc_context({"figure.figsize": (7, 7), "figure.dpi": (200)}):
sc.pl.umap(rna_metacell, color=["celltype"],add_outline=True,outline_color=('white', 'black'),size=10)
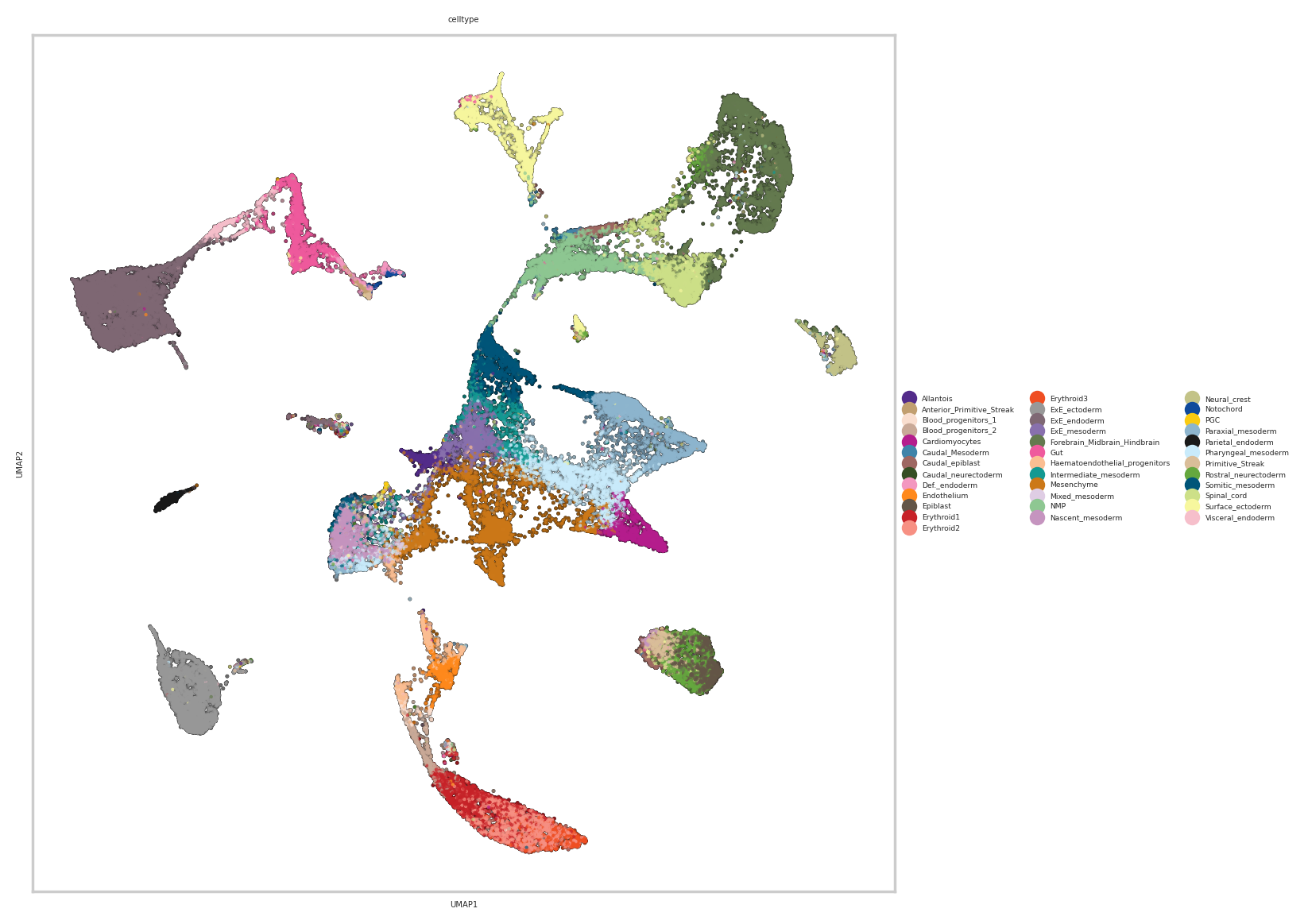
12. Computing average topic activation in different celltypes/groups#
[21]:
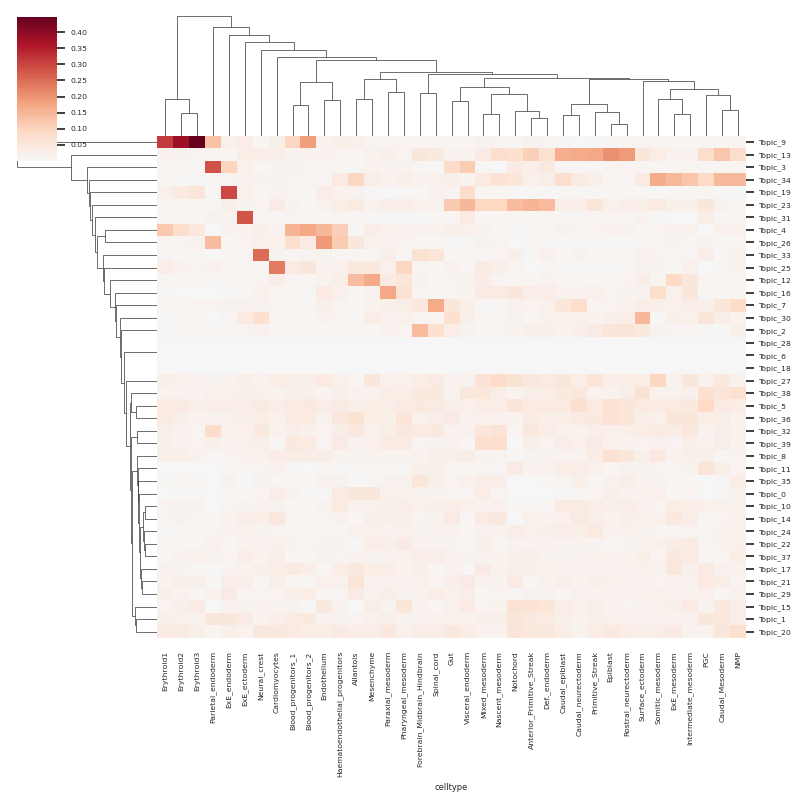
df_topic_celltype = plot_topic_activation_heatmap(rna_metacell, groupby_key=["celltype"], aggregation="mean")
[333]:
sns.histplot(df_topic_celltype.max(axis=1))
[333]:
<Axes: ylabel='Count'>
[337]:
# removing topics not active highly in any of the celltypes
select_topics = ["Topic_" +str(k) for k in np.where(df_topic_celltype.max(axis=1)>0.06)[0]]
[338]:
len(select_topics)
[338]:
25
[339]:
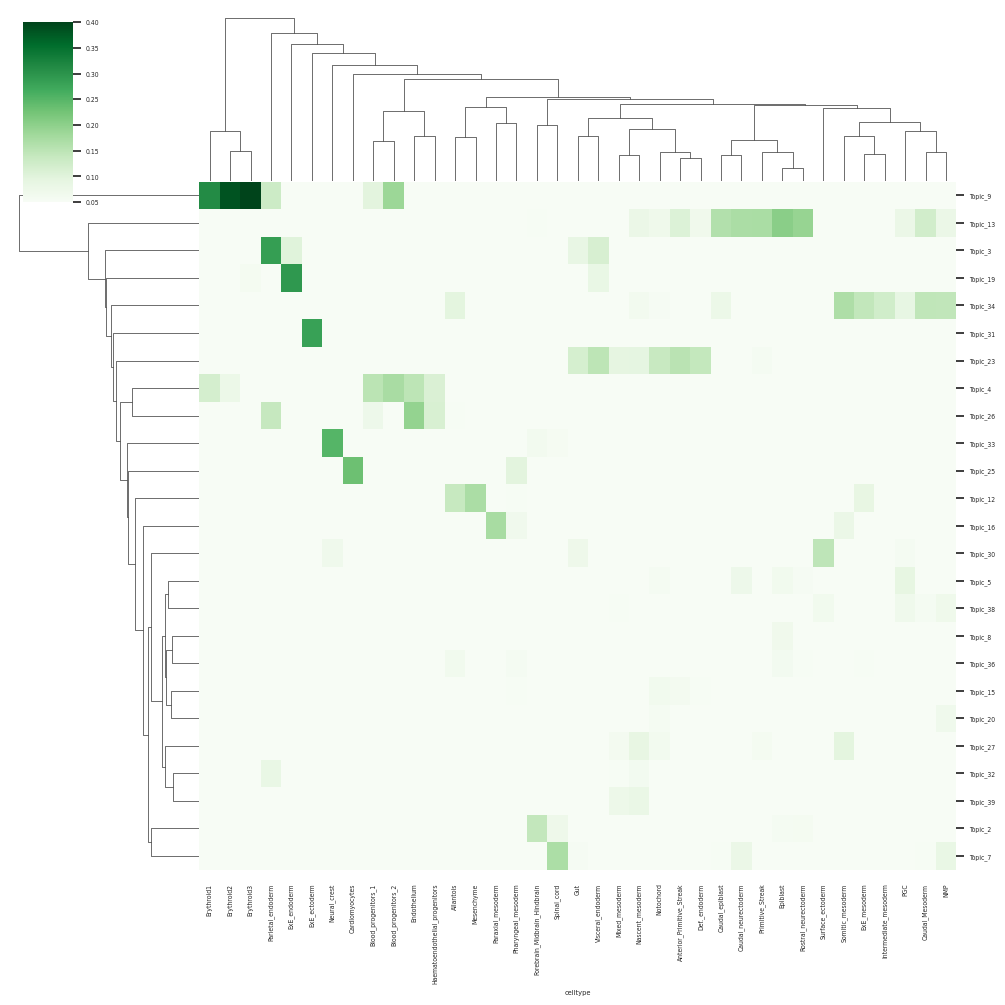
# masking low activations and removing topics not active
%matplotlib inline
sns.set(font_scale = 0.4)
sns.clustermap(df_topic_celltype.loc[select_topics], cmap="Greens", vmin=0.05, vmax=0.4, figsize=(10,10))
[339]:
<seaborn.matrix.ClusterGrid at 0x7f6f65d2ab90>
13. single cell level visualisation of scDoRI Topics#
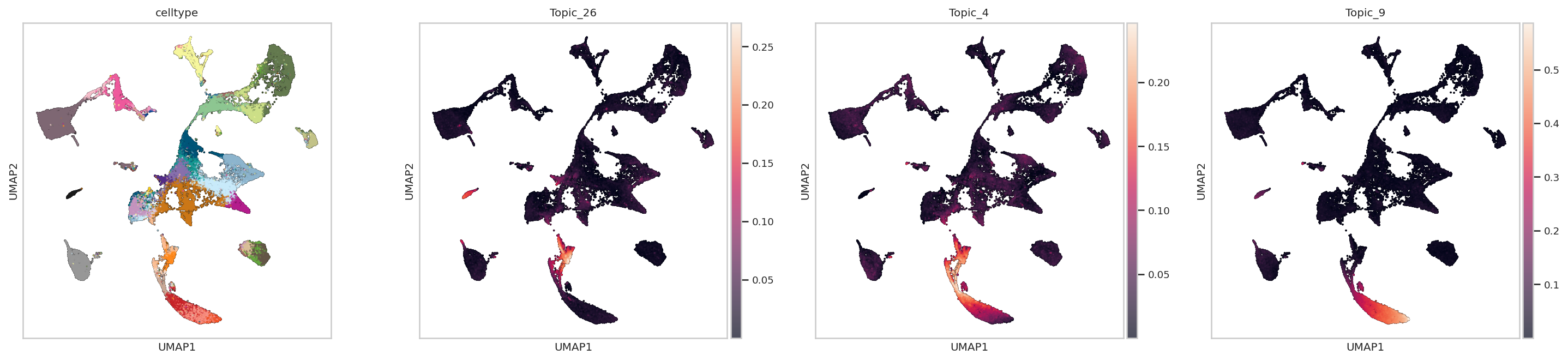
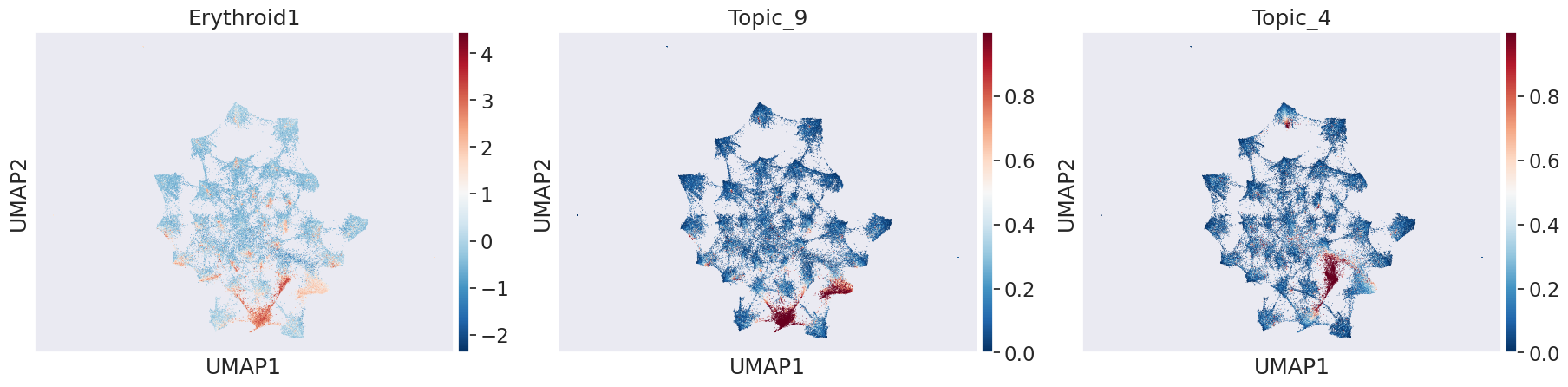
In Erythroid Trajectory from Blood Progenitors to Mature Erythroids: We can see that Topic 26 is active progenitors whereas topic 4 and 9 capture a continuum of erythroid and progenitor programs along the trajectory
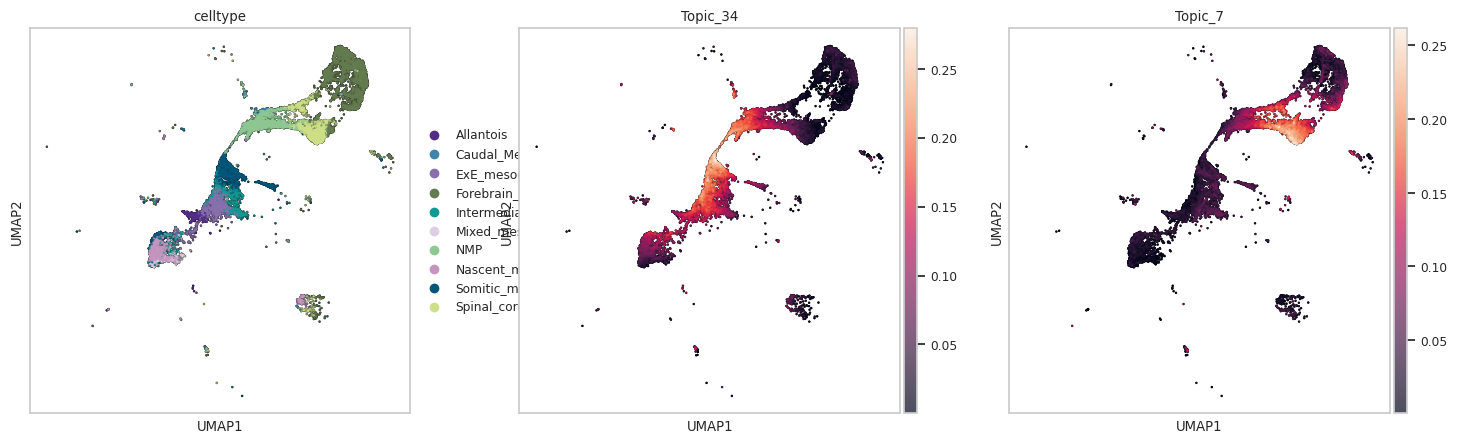
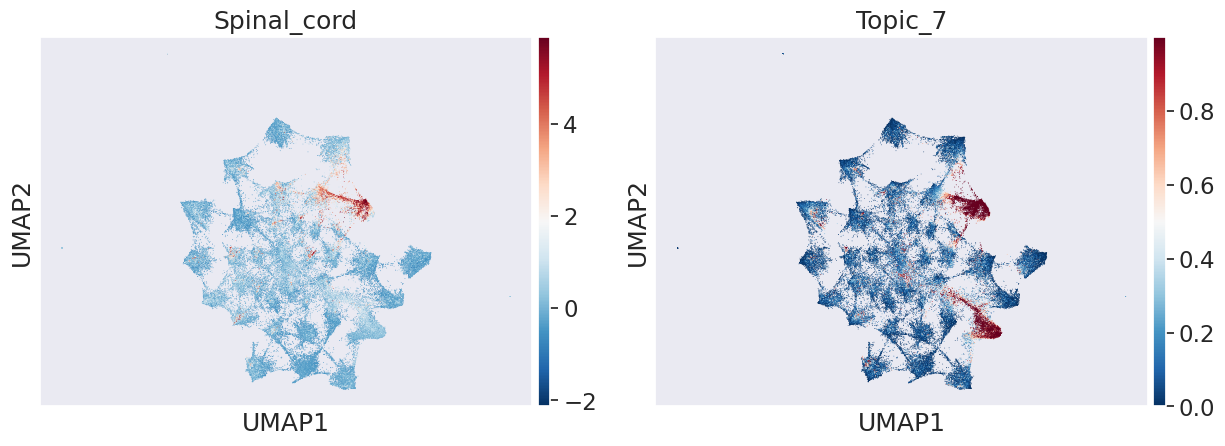
In transition of bipotent progenitors NMP (Meuromesodermal progenitors) to spinal cord or mesodermal lineage: We can see that Topic 34 and 7 capture transition to mesoderm and spinal cord respectively
[23]:
for k in range(config.num_topics):
rna_metacell.obs["Topic_"+str(k)] = scdori_latent[:,k]
[ ]:
sns.set(font_scale = 0.8)
sns.set_style("whitegrid")
with plt.rc_context({"figure.figsize": (5, 5), "figure.dpi": (150)}):
sc.pl.umap(rna_metacell, color=["celltype","Topic_26","Topic_4", "Topic_9"],add_outline=True,outline_color=('white', 'black'),size=10,legend_loc='none')
[41]:
# visualising NMP transitions to Mesoderm [Topic 34] and Spinal Cord [Topic 7] Trajectory
sns.set(font_scale = 0.8)
sns.set_style("whitegrid")
celltype_plot_list = ['Mixed_mesoderm',
'Somitic_mesoderm', 'Nascent_mesoderm','Intermediate_mesoderm','Forebrain_Midbrain_Hindbrain',
'Spinal_cord', 'Caudal_Mesoderm','NMP', 'ExE_mesoderm', 'Allantois']
adata_plot = rna_metacell[rna_metacell.obs.celltype.isin(celltype_plot_list),:]
with plt.rc_context({"figure.figsize": (5, 5), "figure.dpi": (100)}):
sc.pl.umap(adata_plot, color=["celltype","Topic_34", "Topic_7"],add_outline=True,outline_color=('white', 'black'),size=10)
14. Computing Top genes per topic#
this can be used for further analysis such as gene-set enrichment
[ ]:
topic_gene_embedding = compute_topic_gene_matrix(model, device)
INFO:scdori.downstream:Done. computing topic gene matrix shape => torch.Size([40, 4000])
[237]:
sns.clustermap(topic_gene_embedding, vmax=0.01)
/data/saraswat/miniforge3/envs/scdori_test_env/lib/python3.10/site-packages/seaborn/matrix.py:560: UserWarning: Clustering large matrix with scipy. Installing `fastcluster` may give better performance.
warnings.warn(msg)
/data/saraswat/miniforge3/envs/scdori_test_env/lib/python3.10/site-packages/seaborn/matrix.py:560: UserWarning: Clustering large matrix with scipy. Installing `fastcluster` may give better performance.
warnings.warn(msg)
[237]:
<seaborn.matrix.ClusterGrid at 0x7f6e88338460>
15. Performing gene-set enrichment analysis on each topic#
adapted from https://decoupler-py.readthedocs.io/en/latest/notebooks/msigdb.html#MSigDB-gene-sets
users can play around with other gene sets of their choice
[ ]:
#!pip install decoupler
### caution! this can create dependency issues in the conda environment
[262]:
#!pip install liana
[258]:
import decoupler as dc
[265]:
# anndata with topic gene values
adata_gene = sc.AnnData(topic_gene_embedding)
adata_gene.obs.index = ['Topic_' + str(i) for i in range(model.num_topics)]
adata_gene.var.index = [s.upper() for s in rna_metacell.var.index] # dirty and incorrect hack to convert mouse gene names to human
adata_gene.raw=adata_gene
[291]:
# using msigdb
msigdb = dc.get_resource('MSigDB')
[292]:
msigdb['collection'].unique()
[292]:
<StringArray>
[ 'immunesigdb', 'tf_targets_legacy',
'positional', 'cell_type_signatures',
'go_cellular_component', 'chemical_and_genetic_perturbations',
'mirna_targets_mirdb', 'vaccine_response',
'cancer_modules', 'reactome_pathways',
'tf_targets_gtrf', 'go_biological_process',
'go_molecular_function', 'oncogenic_signatures',
'hallmark', 'kegg_pathways',
'pid_pathways', 'human_phenotype_ontology',
'wikipathways', 'cancer_gene_neighborhoods',
'mirna_targets_legacy', 'biocarta_pathways']
Length: 22, dtype: string
[293]:
# using msigdb celltype signature set
msigdb = dc.get_resource('MSigDB')
# Filter by hallmark
msigdb = msigdb[msigdb['collection']=='cell_type_signatures']
# Remove duplicated entries
msigdb = msigdb[~msigdb.duplicated(['geneset', 'genesymbol'])]
msigdb
[293]:
| genesymbol | collection | geneset | |
|---|---|---|---|
| 3 | A1BG | cell_type_signatures | GAO_LARGE_INTESTINE_ADULT_CI_MESENCHYMAL_CELLS |
| 7 | A1BG | cell_type_signatures | HE_LIM_SUN_FETAL_LUNG_C1_PROXIMAL_BASAL_CELL |
| 9 | A1BG | cell_type_signatures | HE_LIM_SUN_FETAL_LUNG_C2_PRE_PDC_DC5_CELL |
| 12 | A1BG | cell_type_signatures | HE_LIM_SUN_FETAL_LUNG_C2_APOE_POS_M2_MACROPHAG... |
| 14 | A1BG | cell_type_signatures | GAUTAM_EYE_CORNEA_MELANOCYTES |
| ... | ... | ... | ... |
| 5521812 | ZYX | cell_type_signatures | BUSSLINGER_DUODENAL_IMMUNE_CELLS |
| 5521814 | ZYX | cell_type_signatures | MANNO_MIDBRAIN_NEUROTYPES_HPERIC |
| 5521818 | ZYX | cell_type_signatures | TRAVAGLINI_LUNG_BRONCHIAL_VESSEL_2_CELL |
| 5521916 | ZZEF1 | cell_type_signatures | GAO_ESOPHAGUS_25W_C4_FGFR1HIGH_EPITHELIAL_CELLS |
| 5522071 | ZZZ3 | cell_type_signatures | MURARO_PANCREAS_BETA_CELL |
192576 rows × 3 columns
[295]:
dc.run_ora(
mat=adata_gene,
net=msigdb,
source='geneset',
target='genesymbol',
verbose=True
)
Running ora on mat with 40 samples and 4000 targets for 775 sources.
[296]:
acts = dc.get_acts(adata_gene, obsm_key='ora_estimate')
# We need to remove inf and set them to the maximum value observed
acts_v = acts.X.ravel()
max_e = np.nanmax(acts_v[np.isfinite(acts_v)])
acts.X[~np.isfinite(acts.X)] = max_e
acts
[296]:
AnnData object with n_obs × n_vars = 40 × 775
obsm: 'ora_estimate', 'ora_pvals'
[298]:
# plot top celltype signatures per topic
df_acts = acts.to_df()
top_programs_per_topic = df_acts.idxmax(axis=1)
unique_top_programs = top_programs_per_topic.unique()
df_topic_program = df_acts.loc[:, unique_top_programs]
[352]:
sns.set(font_scale = 1)
sns.clustermap(df_topic_program.loc[select_topics], figsize=(30,30))
[352]:
<seaborn.matrix.ClusterGrid at 0x7f68f63ef610>
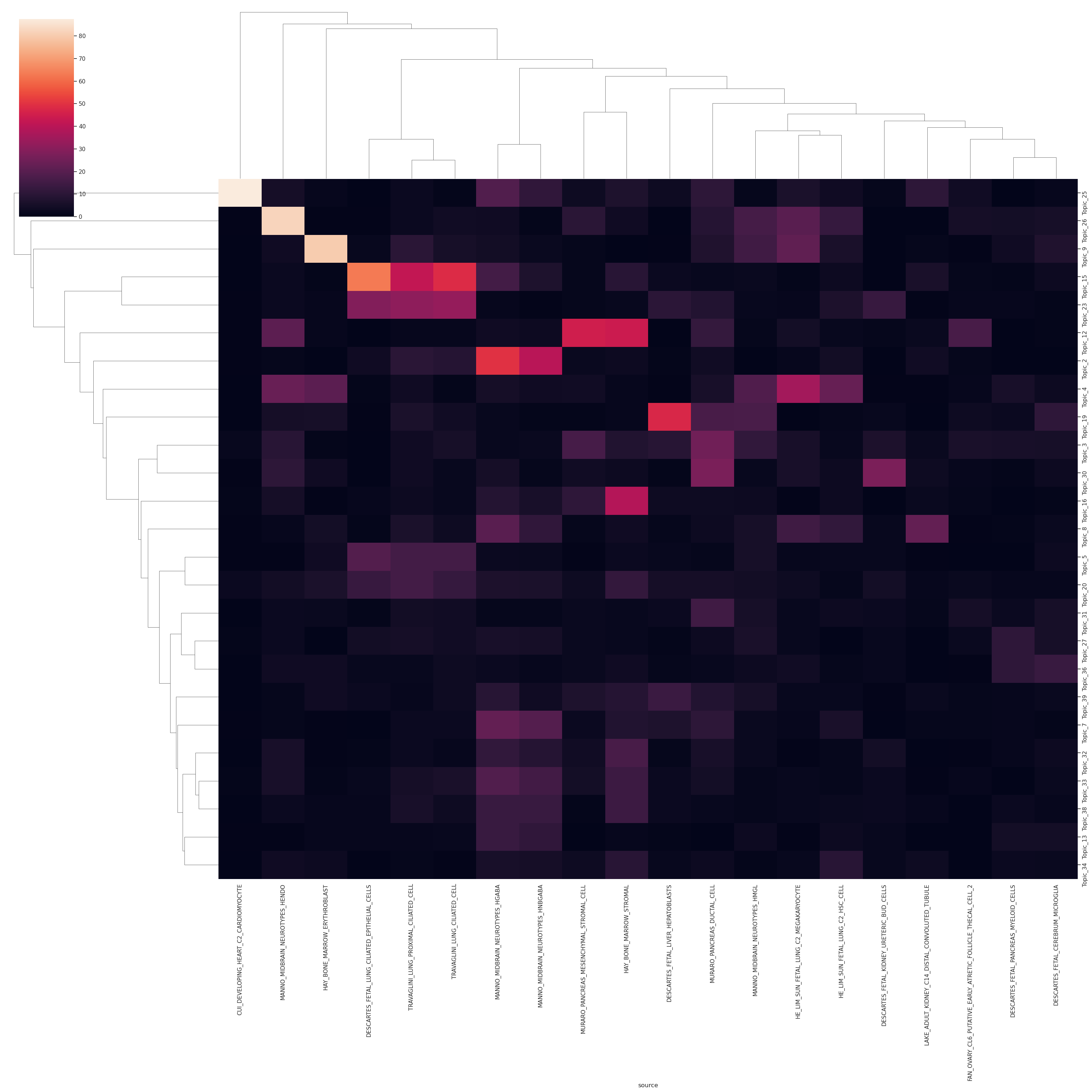
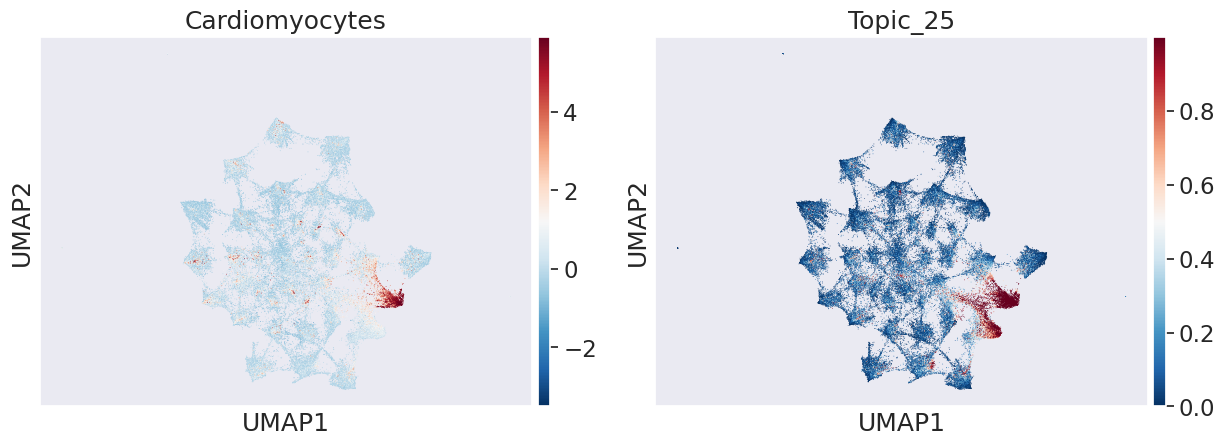
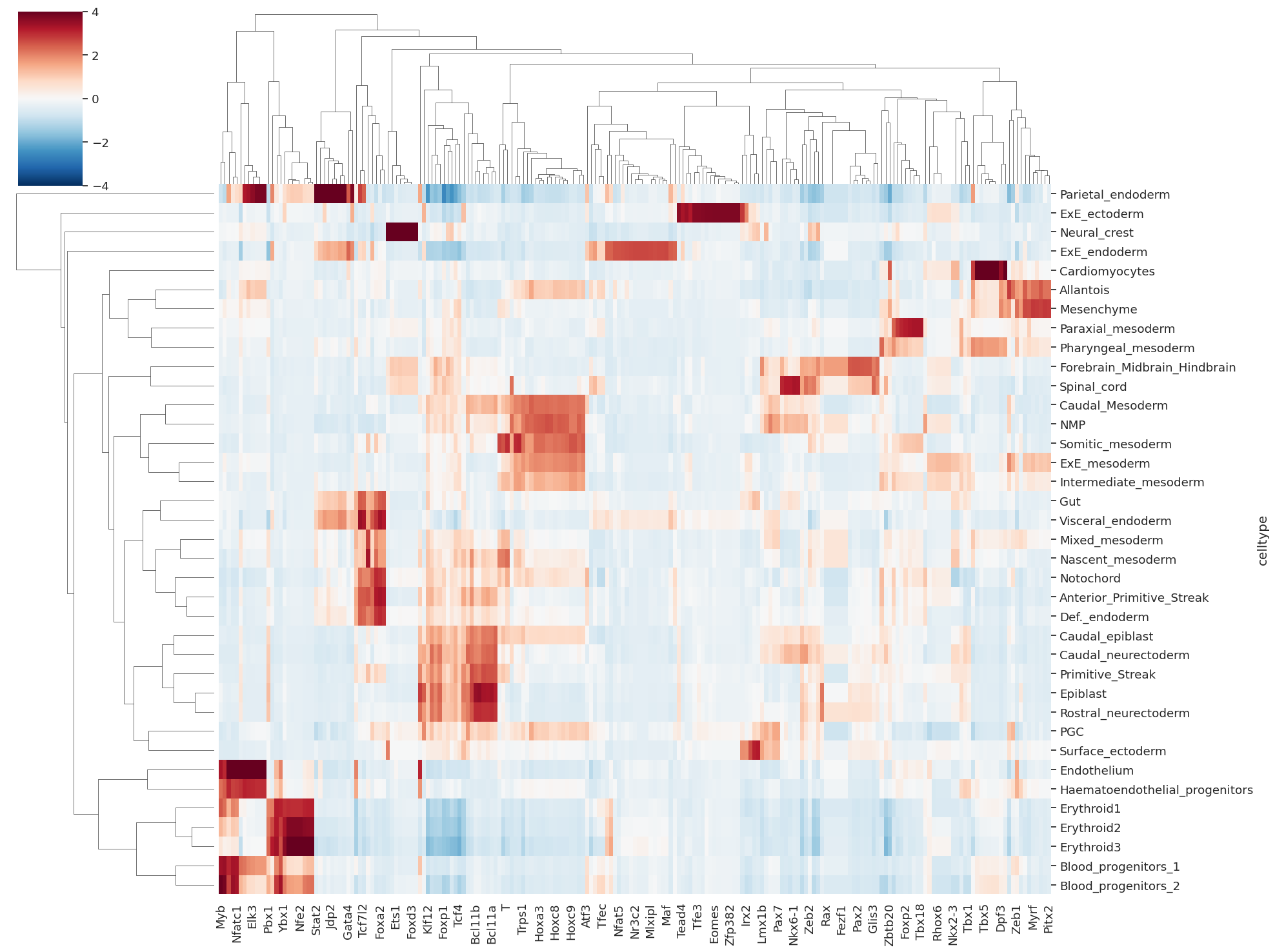
we can see enrichments of respective celltype programs in different topics such Cardiomycoyte in topic 25, Erythroblast in topic 9, Liver hepatoblasts topic 19
16. Computing and visualising peaks associated with each topic#
peaks associated with a topic should capture co-accesibility patterns
we visualise average accesibility of peaks (on a UMAP) in different celltypes and their association to a topic, to see if topics have captured co-accesibility patterns. Each point on the UMAP is a peak.
[29]:
umap_embedding_peaks, topic_peak_embedding = compute_topic_peak_umap(model, device)
/data/saraswat/miniforge3/envs/scdori_test_env/lib/python3.10/site-packages/sklearn/utils/deprecation.py:151: FutureWarning: 'force_all_finite' was renamed to 'ensure_all_finite' in 1.6 and will be removed in 1.8.
warnings.warn(
/data/saraswat/miniforge3/envs/scdori_test_env/lib/python3.10/site-packages/umap/umap_.py:1952: UserWarning: n_jobs value 1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(
INFO:scdori.downstream:Done. umap_embedding_peaks shape => (90000, 2) topic_embedding_peaks shape => (90000, 40)
[30]:
## creating anndata with observations as peaks and values as topic association of each peak
adata_peak = sc.AnnData(topic_peak_embedding)
adata_peak.var.index = ['Topic_' + str(i) for i in range(model.num_topics)]
adata_peak.obs.index = atac_metacell.var.index
adata_peak.obsm["X_umap"] = umap_embedding_peaks
[ ]:
atac_metacell.obs['celltype']=rna_metacell.obs['celltype'].copy()
[32]:
# computing average accesiblity of peaks in each celltype
atac_metacell.layers['counts'] = atac_metacell.X
sc.pp.normalize_total(atac_metacell)
aggregated_atac = sc.get.aggregate(atac_metacell, by="celltype", func=["mean"])
aggregated_atac.X = aggregated_atac.layers['mean']
sc.pp.normalize_total(aggregated_atac)
sc.pp.scale(aggregated_atac)
# adding average accesibility of each peak in a celltype to peak anndata
peak_celltype_df = aggregated_atac.to_df().T
peak_celltype_df = peak_celltype_df.loc[adata_peak.obs.index.values]
adata_peak.obs= pd.concat([adata_peak.obs,peak_celltype_df],axis=1)
[33]:
celltype_name = 'Erythroid1'
sns.set(font_scale = 1.5)
sc.pl.umap(adata_peak, color=[celltype_name,"Topic_9","Topic_4"], cmap='RdBu_r') # topic 9 and 4 are active in erythroids from heatmap above
[34]:
celltype_name = 'NMP'
sns.set(font_scale = 1.5)
sc.pl.umap(adata_peak, color=[celltype_name,"Topic_34","Topic_7"], cmap='RdBu_r')

[35]:
celltype_name = 'Spinal_cord'
sns.set(font_scale = 1.5)
sc.pl.umap(adata_peak, color=[celltype_name,"Topic_7"], cmap='RdBu_r')
[36]:
celltype_name = 'Cardiomyocytes'
sns.set(font_scale = 1.5)
sc.pl.umap(adata_peak, color=[celltype_name,"Topic_25"], cmap='RdBu_r')
17. Visualising TF binding scores on peaks#
[ ]:
## adding insilico chipseq embeddings to peak anndata
tf_names = rna_metacell.var[rna_metacell.var.gene_type=='TF'].index.values
# Create a dictionary for activator and repressor insilico-chipseq binding score
tf_binding_data = {
tf_name + "_activator_binding": insilico_act[:, i].numpy()
for i, tf_name in enumerate(tf_names)
}
tf_binding_data.update({
tf_name + "_repressor_binding": np.abs(insilico_rep[:, i].numpy())
for i, tf_name in enumerate(tf_names)
})
# Convert the dictionary to a DataFrame
tf_binding_data_df = pd.DataFrame(tf_binding_data, index=adata_peak.obs.index)
# Concatenate new columns with existing obs
[39]:
adata_peak.obs = pd.concat([adata_peak.obs, tf_binding_data_df], axis=1)
adata_peak.obs = tf_binding_data_df
[47]:
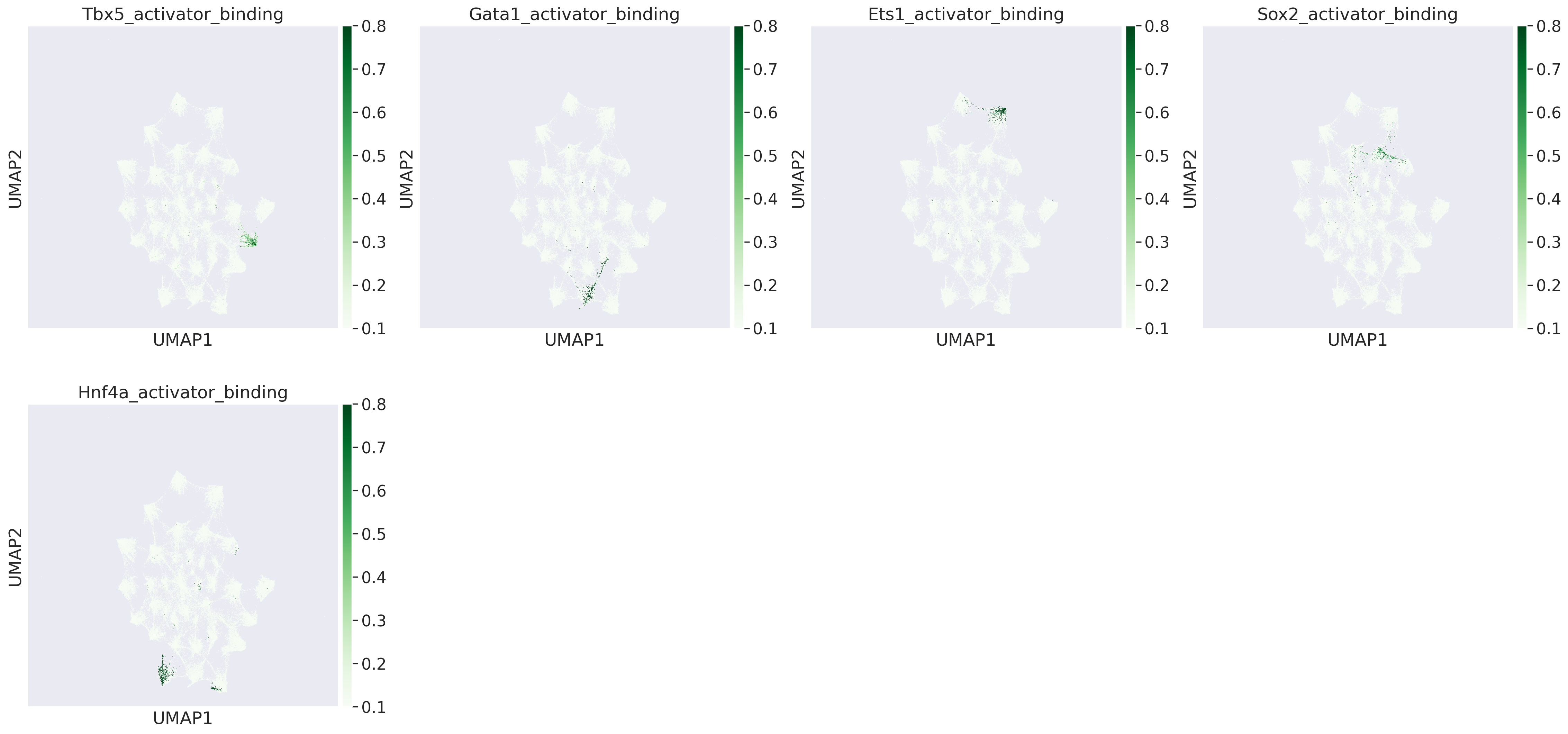
#visualsing TF binding scores on peak umap
sns.set(font_scale = 1.5)
with plt.rc_context({"figure.figsize": (6, 6), "figure.dpi": (200)}):
sc.pl.umap(adata_peak, color=['Tbx5_activator_binding','Gata1_activator_binding','Ets1_activator_binding','Sox2_activator_binding','Hnf4a_activator_binding'], cmap='Greens', vmin=0.1,vmax=0.8,sort_order=True)
Computing eGRNs#
18. Computing ATAC based GRNs with emprirical significance#
these GRNs do not use evidence of TF-gene co-expression
activator GRNs here indicate if within a topic, peaks linked to a gene have accesible binding sites for a TF (from activator insilico-chipseq scores)
repressor GRNs here indicate if within a topic, peaks linked to a gene have non-accesible repressor binding sites for a TF (from repressor insilico-chipseq scores)
additionally we compute a background set of GRN values by shuffling insilico-chipseq scores, which are used to compute empirical significance
[ ]:
grn_act_atac = compute_atac_grn_activator_with_significance(model, device, cutoff_val=0.05,outdir="grn_act_atac")
INFO:scdori.downstream:Computing significant ATAC-derived TF–gene links for activators. Output => grn_act_atac
INFO:scdori.downstream:Processing Topic 1/40
Processing Topic 1/40
Permutations for Topic 1: 100%|██████████| 1000/1000 [00:10<00:00, 92.32it/s]
INFO:scdori.downstream:Processing Topic 2/40
Processing Topic 2/40
Permutations for Topic 2: 100%|██████████| 1000/1000 [00:08<00:00, 114.37it/s]
INFO:scdori.downstream:Processing Topic 3/40
Processing Topic 3/40
Permutations for Topic 3: 100%|██████████| 1000/1000 [00:08<00:00, 114.42it/s]
INFO:scdori.downstream:Processing Topic 4/40
Processing Topic 4/40
Permutations for Topic 4: 100%|██████████| 1000/1000 [00:08<00:00, 114.62it/s]
INFO:scdori.downstream:Processing Topic 5/40
Processing Topic 5/40
Permutations for Topic 5: 100%|██████████| 1000/1000 [00:08<00:00, 115.92it/s]
INFO:scdori.downstream:Processing Topic 6/40
Processing Topic 6/40
Permutations for Topic 6: 100%|██████████| 1000/1000 [00:08<00:00, 116.14it/s]
INFO:scdori.downstream:Processing Topic 7/40
Processing Topic 7/40
Permutations for Topic 7: 100%|██████████| 1000/1000 [00:08<00:00, 115.48it/s]
INFO:scdori.downstream:Processing Topic 8/40
Processing Topic 8/40
Permutations for Topic 8: 100%|██████████| 1000/1000 [00:08<00:00, 123.95it/s]
INFO:scdori.downstream:Processing Topic 9/40
Processing Topic 9/40
Permutations for Topic 9: 100%|██████████| 1000/1000 [00:08<00:00, 123.85it/s]
INFO:scdori.downstream:Processing Topic 10/40
Processing Topic 10/40
Permutations for Topic 10: 100%|██████████| 1000/1000 [00:08<00:00, 123.34it/s]
INFO:scdori.downstream:Processing Topic 11/40
Processing Topic 11/40
Permutations for Topic 11: 100%|██████████| 1000/1000 [00:08<00:00, 123.93it/s]
INFO:scdori.downstream:Processing Topic 12/40
Processing Topic 12/40
Permutations for Topic 12: 100%|██████████| 1000/1000 [00:08<00:00, 123.46it/s]
INFO:scdori.downstream:Processing Topic 13/40
Processing Topic 13/40
Permutations for Topic 13: 100%|██████████| 1000/1000 [00:08<00:00, 123.79it/s]
INFO:scdori.downstream:Processing Topic 14/40
Processing Topic 14/40
Permutations for Topic 14: 100%|██████████| 1000/1000 [00:08<00:00, 123.34it/s]
INFO:scdori.downstream:Processing Topic 15/40
Processing Topic 15/40
Permutations for Topic 15: 100%|██████████| 1000/1000 [00:08<00:00, 123.48it/s]
INFO:scdori.downstream:Processing Topic 16/40
Processing Topic 16/40
Permutations for Topic 16: 100%|██████████| 1000/1000 [00:08<00:00, 123.63it/s]
INFO:scdori.downstream:Processing Topic 17/40
Processing Topic 17/40
Permutations for Topic 17: 100%|██████████| 1000/1000 [00:08<00:00, 122.71it/s]
INFO:scdori.downstream:Processing Topic 18/40
Processing Topic 18/40
Permutations for Topic 18: 100%|██████████| 1000/1000 [00:08<00:00, 123.45it/s]
INFO:scdori.downstream:Processing Topic 19/40
Processing Topic 19/40
Permutations for Topic 19: 100%|██████████| 1000/1000 [00:08<00:00, 123.08it/s]
INFO:scdori.downstream:Processing Topic 20/40
Processing Topic 20/40
Permutations for Topic 20: 100%|██████████| 1000/1000 [00:08<00:00, 123.09it/s]
INFO:scdori.downstream:Processing Topic 21/40
Processing Topic 21/40
Permutations for Topic 21: 100%|██████████| 1000/1000 [00:08<00:00, 123.39it/s]
INFO:scdori.downstream:Processing Topic 22/40
Processing Topic 22/40
Permutations for Topic 22: 100%|██████████| 1000/1000 [00:08<00:00, 123.45it/s]
INFO:scdori.downstream:Processing Topic 23/40
Processing Topic 23/40
Permutations for Topic 23: 100%|██████████| 1000/1000 [00:08<00:00, 123.27it/s]
INFO:scdori.downstream:Processing Topic 24/40
Processing Topic 24/40
Permutations for Topic 24: 100%|██████████| 1000/1000 [00:08<00:00, 122.80it/s]
INFO:scdori.downstream:Processing Topic 25/40
Processing Topic 25/40
Permutations for Topic 25: 100%|██████████| 1000/1000 [00:08<00:00, 122.66it/s]
INFO:scdori.downstream:Processing Topic 26/40
Processing Topic 26/40
Permutations for Topic 26: 100%|██████████| 1000/1000 [00:08<00:00, 116.09it/s]
INFO:scdori.downstream:Processing Topic 27/40
Processing Topic 27/40
Permutations for Topic 27: 100%|██████████| 1000/1000 [00:08<00:00, 116.47it/s]
INFO:scdori.downstream:Processing Topic 28/40
Processing Topic 28/40
Permutations for Topic 28: 100%|██████████| 1000/1000 [00:08<00:00, 115.96it/s]
INFO:scdori.downstream:Processing Topic 29/40
Processing Topic 29/40
Permutations for Topic 29: 100%|██████████| 1000/1000 [00:08<00:00, 115.67it/s]
INFO:scdori.downstream:Processing Topic 30/40
Processing Topic 30/40
Permutations for Topic 30: 100%|██████████| 1000/1000 [00:08<00:00, 116.39it/s]
INFO:scdori.downstream:Processing Topic 31/40
Processing Topic 31/40
Permutations for Topic 31: 100%|██████████| 1000/1000 [00:08<00:00, 116.28it/s]
INFO:scdori.downstream:Processing Topic 32/40
Processing Topic 32/40
Permutations for Topic 32: 100%|██████████| 1000/1000 [00:08<00:00, 116.13it/s]
INFO:scdori.downstream:Processing Topic 33/40
Processing Topic 33/40
Permutations for Topic 33: 100%|██████████| 1000/1000 [00:08<00:00, 116.69it/s]
INFO:scdori.downstream:Processing Topic 34/40
Processing Topic 34/40
Permutations for Topic 34: 100%|██████████| 1000/1000 [00:08<00:00, 115.79it/s]
INFO:scdori.downstream:Processing Topic 35/40
Processing Topic 35/40
Permutations for Topic 35: 100%|██████████| 1000/1000 [00:08<00:00, 115.62it/s]
INFO:scdori.downstream:Processing Topic 36/40
Processing Topic 36/40
Permutations for Topic 36: 100%|██████████| 1000/1000 [00:08<00:00, 115.21it/s]
INFO:scdori.downstream:Processing Topic 37/40
Processing Topic 37/40
Permutations for Topic 37: 100%|██████████| 1000/1000 [00:08<00:00, 115.31it/s]
INFO:scdori.downstream:Processing Topic 38/40
Processing Topic 38/40
Permutations for Topic 38: 100%|██████████| 1000/1000 [00:08<00:00, 115.78it/s]
INFO:scdori.downstream:Processing Topic 39/40
Processing Topic 39/40
Permutations for Topic 39: 100%|██████████| 1000/1000 [00:08<00:00, 114.76it/s]
INFO:scdori.downstream:Processing Topic 40/40
Processing Topic 40/40
Permutations for Topic 40: 100%|██████████| 1000/1000 [00:08<00:00, 115.43it/s]
INFO:scdori.downstream:Completed computing activator ATAC GRNs.
[93]:
# ATAC based GRN for repressors
grn_rep_atac = compute_atac_grn_repressor_with_significance(model, device, cutoff_val=0.05,outdir="grn_act_atac")
INFO:scdori.downstream:Computing significant ATAC-derived TF–gene links for repressors. Output => grn_act_atac
INFO:scdori.downstream:Processing Topic 1/40
Processing Topic 1/40
Permutations for Topic 1: 100%|██████████| 1000/1000 [00:09<00:00, 101.86it/s]
INFO:scdori.downstream:Processing Topic 2/40
Processing Topic 2/40
Permutations for Topic 2: 100%|██████████| 1000/1000 [00:08<00:00, 114.26it/s]
INFO:scdori.downstream:Processing Topic 3/40
Processing Topic 3/40
Permutations for Topic 3: 100%|██████████| 1000/1000 [00:08<00:00, 113.47it/s]
INFO:scdori.downstream:Processing Topic 4/40
Processing Topic 4/40
Permutations for Topic 4: 100%|██████████| 1000/1000 [00:08<00:00, 114.23it/s]
INFO:scdori.downstream:Processing Topic 5/40
Processing Topic 5/40
Permutations for Topic 5: 100%|██████████| 1000/1000 [00:08<00:00, 114.07it/s]
INFO:scdori.downstream:Processing Topic 6/40
Processing Topic 6/40
Permutations for Topic 6: 100%|██████████| 1000/1000 [00:08<00:00, 114.09it/s]
INFO:scdori.downstream:Processing Topic 7/40
Processing Topic 7/40
Permutations for Topic 7: 100%|██████████| 1000/1000 [00:08<00:00, 113.92it/s]
INFO:scdori.downstream:Processing Topic 8/40
Processing Topic 8/40
Permutations for Topic 8: 100%|██████████| 1000/1000 [00:08<00:00, 114.17it/s]
INFO:scdori.downstream:Processing Topic 9/40
Processing Topic 9/40
Permutations for Topic 9: 100%|██████████| 1000/1000 [00:08<00:00, 115.26it/s]
INFO:scdori.downstream:Processing Topic 10/40
Processing Topic 10/40
Permutations for Topic 10: 100%|██████████| 1000/1000 [00:08<00:00, 114.98it/s]
INFO:scdori.downstream:Processing Topic 11/40
Processing Topic 11/40
Permutations for Topic 11: 100%|██████████| 1000/1000 [00:08<00:00, 115.78it/s]
INFO:scdori.downstream:Processing Topic 12/40
Processing Topic 12/40
Permutations for Topic 12: 100%|██████████| 1000/1000 [00:08<00:00, 115.73it/s]
INFO:scdori.downstream:Processing Topic 13/40
Processing Topic 13/40
Permutations for Topic 13: 100%|██████████| 1000/1000 [00:08<00:00, 115.83it/s]
INFO:scdori.downstream:Processing Topic 14/40
Processing Topic 14/40
Permutations for Topic 14: 100%|██████████| 1000/1000 [00:08<00:00, 115.58it/s]
INFO:scdori.downstream:Processing Topic 15/40
Processing Topic 15/40
Permutations for Topic 15: 100%|██████████| 1000/1000 [00:08<00:00, 115.50it/s]
INFO:scdori.downstream:Processing Topic 16/40
Processing Topic 16/40
Permutations for Topic 16: 100%|██████████| 1000/1000 [00:08<00:00, 115.45it/s]
INFO:scdori.downstream:Processing Topic 17/40
Processing Topic 17/40
Permutations for Topic 17: 100%|██████████| 1000/1000 [00:08<00:00, 115.75it/s]
INFO:scdori.downstream:Processing Topic 18/40
Processing Topic 18/40
Permutations for Topic 18: 100%|██████████| 1000/1000 [00:08<00:00, 115.75it/s]
INFO:scdori.downstream:Processing Topic 19/40
Processing Topic 19/40
Permutations for Topic 19: 100%|██████████| 1000/1000 [00:08<00:00, 115.86it/s]
INFO:scdori.downstream:Processing Topic 20/40
Processing Topic 20/40
Permutations for Topic 20: 100%|██████████| 1000/1000 [00:08<00:00, 115.38it/s]
INFO:scdori.downstream:Processing Topic 21/40
Processing Topic 21/40
Permutations for Topic 21: 100%|██████████| 1000/1000 [00:08<00:00, 114.69it/s]
INFO:scdori.downstream:Processing Topic 22/40
Processing Topic 22/40
Permutations for Topic 22: 100%|██████████| 1000/1000 [00:08<00:00, 115.21it/s]
INFO:scdori.downstream:Processing Topic 23/40
Processing Topic 23/40
Permutations for Topic 23: 100%|██████████| 1000/1000 [00:08<00:00, 114.96it/s]
INFO:scdori.downstream:Processing Topic 24/40
Processing Topic 24/40
Permutations for Topic 24: 100%|██████████| 1000/1000 [00:08<00:00, 115.71it/s]
INFO:scdori.downstream:Processing Topic 25/40
Processing Topic 25/40
Permutations for Topic 25: 100%|██████████| 1000/1000 [00:08<00:00, 114.75it/s]
INFO:scdori.downstream:Processing Topic 26/40
Processing Topic 26/40
Permutations for Topic 26: 100%|██████████| 1000/1000 [00:08<00:00, 115.05it/s]
INFO:scdori.downstream:Processing Topic 27/40
Processing Topic 27/40
Permutations for Topic 27: 100%|██████████| 1000/1000 [00:08<00:00, 114.17it/s]
INFO:scdori.downstream:Processing Topic 28/40
Processing Topic 28/40
Permutations for Topic 28: 100%|██████████| 1000/1000 [00:08<00:00, 115.04it/s]
INFO:scdori.downstream:Processing Topic 29/40
Processing Topic 29/40
Permutations for Topic 29: 100%|██████████| 1000/1000 [00:08<00:00, 116.19it/s]
INFO:scdori.downstream:Processing Topic 30/40
Processing Topic 30/40
Permutations for Topic 30: 100%|██████████| 1000/1000 [00:08<00:00, 114.97it/s]
INFO:scdori.downstream:Processing Topic 31/40
Processing Topic 31/40
Permutations for Topic 31: 100%|██████████| 1000/1000 [00:08<00:00, 115.75it/s]
INFO:scdori.downstream:Processing Topic 32/40
Processing Topic 32/40
Permutations for Topic 32: 100%|██████████| 1000/1000 [00:08<00:00, 122.56it/s]
INFO:scdori.downstream:Processing Topic 33/40
Processing Topic 33/40
Permutations for Topic 33: 100%|██████████| 1000/1000 [00:08<00:00, 122.81it/s]
INFO:scdori.downstream:Processing Topic 34/40
Processing Topic 34/40
Permutations for Topic 34: 100%|██████████| 1000/1000 [00:08<00:00, 122.83it/s]
INFO:scdori.downstream:Processing Topic 35/40
Processing Topic 35/40
Permutations for Topic 35: 100%|██████████| 1000/1000 [00:08<00:00, 122.70it/s]
INFO:scdori.downstream:Processing Topic 36/40
Processing Topic 36/40
Permutations for Topic 36: 100%|██████████| 1000/1000 [00:08<00:00, 123.16it/s]
INFO:scdori.downstream:Processing Topic 37/40
Processing Topic 37/40
Permutations for Topic 37: 100%|██████████| 1000/1000 [00:08<00:00, 123.06it/s]
INFO:scdori.downstream:Processing Topic 38/40
Processing Topic 38/40
Permutations for Topic 38: 100%|██████████| 1000/1000 [00:08<00:00, 122.79it/s]
INFO:scdori.downstream:Processing Topic 39/40
Processing Topic 39/40
Permutations for Topic 39: 100%|██████████| 1000/1000 [00:08<00:00, 114.53it/s]
INFO:scdori.downstream:Processing Topic 40/40
Processing Topic 40/40
Permutations for Topic 40: 100%|██████████| 1000/1000 [00:08<00:00, 115.03it/s]
INFO:scdori.downstream:Completed computing repressor ATAC GRNs.
19. Computing final GRNs#
to compute these, we use the significant ATAC based GRNs derived previously and do element wise product with GRNs learnt by scDoRI incorproating TF - gene co-expression
[40]:
# calculating TF-expression per topic
# either from scdori model weights or from true data
#using true expression here
tf_normalised = get_tf_expression("True",model, device, all_dataset_loader,rna_metacell,atac_metacell,num_cells,tf_indices,onehot_batch,config)
Extracting latent topics: 100%|██████████| 112/112 [01:27<00:00, 1.28it/s]
[67]:
tf_normalised.shape
[67]:
torch.Size([40, 300])
[41]:
# compute final GRNs which use the significant ATAC based GRNs derived above
grn_act, grn_rep = compute_significant_grn(model, device, cutoff_val_activator=0.05,cutoff_val_repressor=0.05, tf_normalised=tf_normalised.detach().cpu().numpy(), outdir="grn_act_atac")
INFO:scdori.downstream:Loading ATAC-derived GRNs...
INFO:scdori.downstream:Computing combined GRNs...
INFO:scdori.downstream:Saving computed GRNs...
INFO:scdori.downstream:GRN computation completed successfully.
[ ]:
# save regulons per TF
save_regulons(grn_act, tf_names=tf_names, gene_names=rna_metacell.var.index.values, num_topics=model.num_topics, output_dir="grn_act_atac", mode="activator")
[ ]:
# save regulons per TF
save_regulons(grn_rep, tf_names=tf_names, gene_names=rna_metacell.var.index.values, num_topics=model.num_topics, output_dir="grn_act_atac", mode="repressor")
[48]:
# loading saved GRN
grn_act = np.load('grn_act_atac/grn_activator__0.05.npy')
grn_rep= np.load('grn_act_atac/grn_repressor__0.05.npy')
[49]:
grn_act.shape # num_topics x num_tfs x num_genes
[49]:
(40, 300, 4000)
20. Computing and plotting top activator TFs per topic#
[50]:
# plotting TF activity across topics
tf_names = rna_metacell.var[rna_metacell.var.gene_type=='TF'].index.values
# plot top k activators per topic
df_topic_activator, top_regulators = get_top_activators_per_topic(
grn_act,
tf_names,
scdori_latent,
selected_topics=None,
top_k=2,
clamp_value=1e-8,
zscore=True,
figsize=(25, 10),
out_fig=None
)
INFO:scdori.downstream:=== Plotting top activator regulators per topic ===
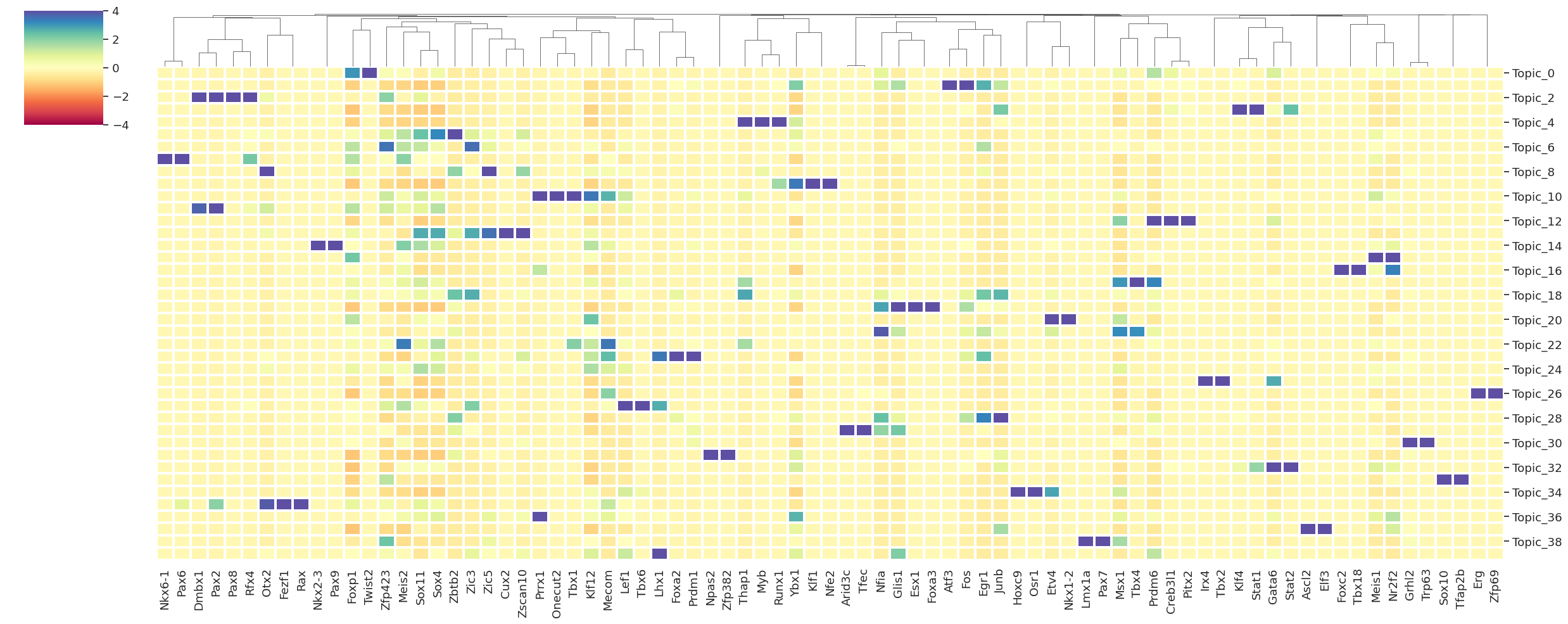
INFO:scdori.downstream:=== Done plotting top regulators per topic ===
[51]:
df_topic_activator # matrix of Topic TF activities
[51]:
| Alx1 | Ar | Arid3c | Arid5b | Ascl1 | Ascl2 | Atf3 | Barx1 | Batf3 | Bcl11a | ... | Zfp523 | Zfp69 | Zfp711 | Zic1 | Zic2 | Zic3 | Zic4 | Zic5 | Zscan10 | Zscan4c | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Topic_0 | 0.0 | 0.0 | -0.158113 | -0.113955 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | 0.164900 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_1 | 0.0 | 0.0 | -0.158113 | 2.412600 | 0.0 | -0.158113 | 6.166309 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_2 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_3 | 0.0 | 0.0 | -0.158113 | 1.709113 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_4 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | 0.283313 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_5 | 0.0 | 0.0 | -0.158113 | -0.479874 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | 0.624574 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 1.990908 | 0.903295 | 0.0 | 0.419149 | 1.018452 | 0.0 |
| Topic_6 | 0.0 | 0.0 | -0.158113 | -0.044312 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | 3.561999 | 0.0 | 0.685740 | 0.145646 | 0.0 |
| Topic_7 | 0.0 | 0.0 | -0.158113 | -0.598857 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_8 | 0.0 | 0.0 | -0.158113 | -0.529142 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | 2.522007 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 0.289952 | 0.114372 | 0.0 | 4.639709 | 1.842462 | 0.0 |
| Topic_9 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_10 | 0.0 | 0.0 | -0.158113 | -0.373513 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.102275 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_11 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_12 | 0.0 | 0.0 | -0.158113 | -0.072807 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | 0.112615 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_13 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | 5.366496 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 2.602772 | 2.711501 | 0.0 | 3.513520 | 5.409577 | 0.0 |
| Topic_14 | 0.0 | 0.0 | -0.158113 | -0.406806 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.023502 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.217899 | 0.0 |
| Topic_15 | 0.0 | 0.0 | -0.158113 | -0.282287 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | 0.024857 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_16 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.331571 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_17 | 0.0 | 0.0 | -0.158113 | -0.150101 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | 0.050481 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.305153 | 0.0 |
| Topic_18 | 0.0 | 0.0 | -0.158113 | 0.345635 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | 2.662320 | 0.0 | -0.348377 | 0.222181 | 0.0 |
| Topic_19 | 0.0 | 0.0 | -0.158113 | 1.664095 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_20 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.325911 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_21 | 0.0 | 0.0 | -0.158113 | 2.591520 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.177927 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.283884 | 0.0 |
| Topic_22 | 0.0 | 0.0 | -0.158113 | -0.562149 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.147956 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_23 | 0.0 | 0.0 | -0.158113 | 0.051448 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | 0.108123 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 0.153288 | 0.652382 | 0.0 | -0.158550 | 0.971483 | 0.0 |
| Topic_24 | 0.0 | 0.0 | -0.158113 | -0.263331 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | 0.463549 | ... | 0.0 | -0.158114 | -0.158753 | 0.0 | 0.764304 | -0.431009 | 0.0 | 0.097052 | 0.169522 | 0.0 |
| Topic_25 | 0.0 | 0.0 | -0.158113 | -0.677782 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_26 | 0.0 | 0.0 | -0.158113 | -0.667436 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | 6.166433 | 6.115410 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_27 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | 2.092698 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_28 | 0.0 | 0.0 | -0.158113 | 1.328635 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_29 | 0.0 | 0.0 | 6.166414 | 2.135152 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.028738 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_30 | 0.0 | 0.0 | -0.158113 | -0.248851 | 0.0 | -0.158113 | -0.158110 | 0.0 | 3.723565 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | 0.235461 | 0.0 |
| Topic_31 | 0.0 | 0.0 | -0.158113 | 0.015134 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.298730 | -0.431009 | 0.0 | -0.129481 | -0.348830 | 0.0 |
| Topic_32 | 0.0 | 0.0 | -0.158113 | -0.270752 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_33 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_34 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_35 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 0.734621 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_36 | 0.0 | 0.0 | -0.158113 | 0.048776 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | 0.080043 | 0.0 | -0.237916 | -0.431009 | 0.0 | 0.683270 | 0.336786 | 0.0 |
| Topic_37 | 0.0 | 0.0 | -0.158113 | 2.345082 | 0.0 | 6.166427 | -0.158110 | 0.0 | 4.818160 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | -0.365167 | -0.431009 | 0.0 | -0.348377 | -0.370249 | 0.0 |
| Topic_38 | 0.0 | 0.0 | -0.158113 | -0.634754 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | -0.286531 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 4.788070 | -0.431009 | 0.0 | 0.547308 | -0.370249 | 0.0 |
| Topic_39 | 0.0 | 0.0 | -0.158113 | -0.689207 | 0.0 | -0.158113 | -0.158110 | 0.0 | -0.224782 | 0.657307 | ... | 0.0 | -0.158114 | -0.222186 | 0.0 | 0.094880 | 0.691460 | 0.0 | 0.153598 | 0.430678 | 0.0 |
40 rows × 300 columns
21. Computing and plotting TF activity per cell#
[52]:
# computing TF activity per cell
cell_tf_act = compute_activator_tf_activity_per_cell(
grn_act,
tf_names,
scdori_latent,
selected_topics=None,
clamp_value=1e-8,
zscore=True
)
INFO:scdori.downstream:=== Computing TF activity per cell ===
[53]:
# aggregating activity per celltype
df_celltype_tf = pd.DataFrame(cell_tf_act, columns=tf_names)
df_celltype_tf['celltype'] = rna_metacell.obs['celltype'].values
df_celltype_tf=df_celltype_tf.groupby('celltype').mean()
df_celltype_tf=df_celltype_tf.fillna(0)
df_celltype_tf = df_celltype_tf.loc[:, (df_celltype_tf != 0).any(axis=0)] # removing TF with 0/Nan activity
/tmp/ipykernel_220372/1244025385.py:4: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
df_celltype_tf=df_celltype_tf.groupby('celltype').mean()
[55]:
# top TFs per celltype
for k in df_celltype_tf.index:
print(df_celltype_tf.loc[k].sort_values(ascending=False)[:5])
Msx1 2.812401
Pitx1 2.482060
Prdm6 2.420417
Tbx4 2.246442
Plagl1 2.209494
Name: Allantois, dtype: float32
Foxa2 3.318382
Sp5 3.230514
Prdm1 3.220130
Lhx1 2.549573
Tcf7l2 2.466181
Name: Anterior_Primitive_Streak, dtype: float32
Thap1 3.457717
Myb 3.403746
Fli1 3.332256
Nfatc1 3.291261
Hhex 3.053652
Name: Blood_progenitors_1, dtype: float32
Myb 3.962984
Thap1 3.834107
Fli1 3.445354
Runx1 3.366277
Nfatc1 3.314607
Name: Blood_progenitors_2, dtype: float32
Nkx2-5 4.915843
Tbx2 4.889453
Irx4 4.889432
Tbx5 4.846557
Esrrg 4.772815
Name: Cardiomyocytes, dtype: float32
Cdx2 2.382280
Hoxb9 2.251371
Hoxb8 2.235967
Hoxa7 2.233847
Hoxb4 2.232038
Name: Caudal_Mesoderm, dtype: float32
Cux2 2.315070
Bcl11a 2.111253
Zic3 2.101088
Pou5f1 2.095708
Zscan10 2.075776
Name: Caudal_epiblast, dtype: float32
Cux2 2.459110
Zscan10 2.317297
Bcl11a 2.295461
Zic2 2.286987
Pou5f1 2.271102
Name: Caudal_neurectoderm, dtype: float32
Foxa2 3.013058
Prdm1 2.905914
Sp5 2.884930
Sox17 2.415743
Tcf7l2 2.328682
Name: Def._endoderm, dtype: float32
Irf2 5.552412
Elk3 5.518743
Zfp69 5.487562
Erg 5.487561
Nr5a2 5.487561
Name: Endothelium, dtype: float32
Zic5 3.557174
Bcl11b 3.491947
Bcl11a 3.369754
Pou5f1 3.333444
Zscan10 3.289199
Name: Epiblast, dtype: float32
Rreb1 3.154777
Gfi1b 3.113449
Runx1 3.113264
E2f2 3.106583
Gata1 3.080394
Name: Erythroid1, dtype: float32
Nfe2 3.708780
Klf1 3.708776
Foxo3 3.698624
Jun 3.691791
Gata1 3.602191
Name: Erythroid2, dtype: float32
Nfe2 4.405540
Klf1 4.405535
Jun 4.351606
Foxo3 4.351569
Gata1 4.113173
Name: Erythroid3, dtype: float32
Elf5 3.741948
Zfp382 3.741423
Nr4a1 3.741415
Npas2 3.741409
Esrrb 3.737677
Name: ExE_ectoderm, dtype: float32
Maf 2.658887
Nr3c2 2.658283
Esx1 2.657149
Foxa3 2.657129
Nfatc2 2.657127
Name: ExE_endoderm, dtype: float32
Osr1 2.054457
Hoxc9 2.054455
Hoxd4 1.987622
Hoxc6 1.947457
Hoxa7 1.909860
Name: ExE_mesoderm, dtype: float32
Otx1 2.527822
Pax2 2.510998
Pax8 2.489977
Pax5 2.481016
En1 2.467573
Name: Forebrain_Midbrain_Hindbrain, dtype: float32
Prdm1 2.518131
Sox17 2.458320
Foxa2 2.443587
Tcf7l2 2.397369
Sp5 2.148218
Name: Gut, dtype: float32
Irf2 3.099161
Hhex 3.060217
Zfp711 3.056182
Elk3 3.024903
Zfp69 2.948663
Name: Haematoendothelial_progenitors, dtype: float32
Osr1 1.688312
Hoxc9 1.688310
Hoxb1 1.664535
Hes7 1.655115
Hoxd4 1.594885
Name: Intermediate_mesoderm, dtype: float32
Creb3l1 2.819529
Myrf 2.815305
Plagl1 2.809360
Pitx2 2.791425
Pitx1 2.728289
Name: Mesenchyme, dtype: float32
Lhx1 2.732252
Sp5 1.933315
Foxa2 1.605808
Prdm1 1.563257
Mecom 1.357563
Name: Mixed_mesoderm, dtype: float32
Hoxb9 2.574918
Hoxc4 2.534038
Hoxb4 2.478113
Hoxa3 2.455356
Hoxa9 2.437630
Name: NMP, dtype: float32
Lhx1 3.333681
Sp5 2.254464
T 2.248332
Lef1 2.052773
Tbx6 2.003616
Name: Nascent_mesoderm, dtype: float32
Tfap2b 5.577940
Foxd3 5.577939
Sox10 5.577938
Ets1 5.574512
Sox9 5.568067
Name: Neural_crest, dtype: float32
Sp5 3.020447
Foxa2 2.908019
Prdm1 2.750876
Egr1 2.424358
Sox17 2.161388
Name: Notochord, dtype: float32
Zbtb2 1.922414
Zic2 1.731415
Pax7 1.538206
Lmx1a 1.538201
Cdx2 1.494526
Name: PGC, dtype: float32
Foxc2 3.293137
Tbx18 3.293136
Meox1 3.292907
Six1 3.227916
Foxp2 3.137960
Name: Paraxial_mesoderm, dtype: float32
Sox7 6.944213
Jdp2 6.408046
Snai1 6.376996
Stat1 6.172889
Klf5 6.024989
Name: Parietal_endoderm, dtype: float32
Meis1 2.291860
Gata6 1.885065
Nr2f2 1.827772
Esrrg 1.799770
Mef2c 1.728161
Name: Pharyngeal_mesoderm, dtype: float32
Zic3 2.615363
Pou5f1 2.614649
Zscan10 2.540146
Bcl11a 2.537390
Cux2 2.510679
Name: Primitive_Streak, dtype: float32
Zic5 2.991289
Bcl11b 2.979502
Bcl11a 2.973205
Zscan10 2.922971
Pou5f1 2.922059
Name: Rostral_neurectoderm, dtype: float32
Hoxb1 3.046862
Hes7 2.999344
T 2.960349
Tbx6 2.700277
Lef1 2.546784
Name: Somitic_mesoderm, dtype: float32
Nkx6-1 3.304471
Pax6 3.275482
Foxb1 3.182235
Rarb 3.176786
Hes5 3.051524
Name: Spinal_cord, dtype: float32
Trp63 3.160946
Grhl2 3.118778
Batf3 2.599621
Tfap2a 2.041930
Gata3 1.862946
Name: Surface_ectoderm, dtype: float32
Sox17 3.455087
Foxa2 3.350312
Tcf7l2 3.288827
Prdm1 3.182143
Sp5 2.886621
Name: Visceral_endoderm, dtype: float32
[56]:
sns.clustermap(df_celltype_tf, cmap='RdBu_r', vmin=-4, vmax=4, figsize=(20,15))
[56]:
<seaborn.matrix.ClusterGrid at 0x7f6ecd083190>
[57]:
# visualing TF activity on UMAP
df_cell_tf = pd.DataFrame(cell_tf_act, columns=[s+'_activity' for s in tf_names])
df_cell_tf.index=rna_metacell.obs.index.values
obs_df = pd.concat([rna_metacell.obs,df_cell_tf],axis=1)
[ ]:
for k in df_cell_tf.columns:
rna_metacell.obs[k]=df_cell_tf[k].values
[64]:
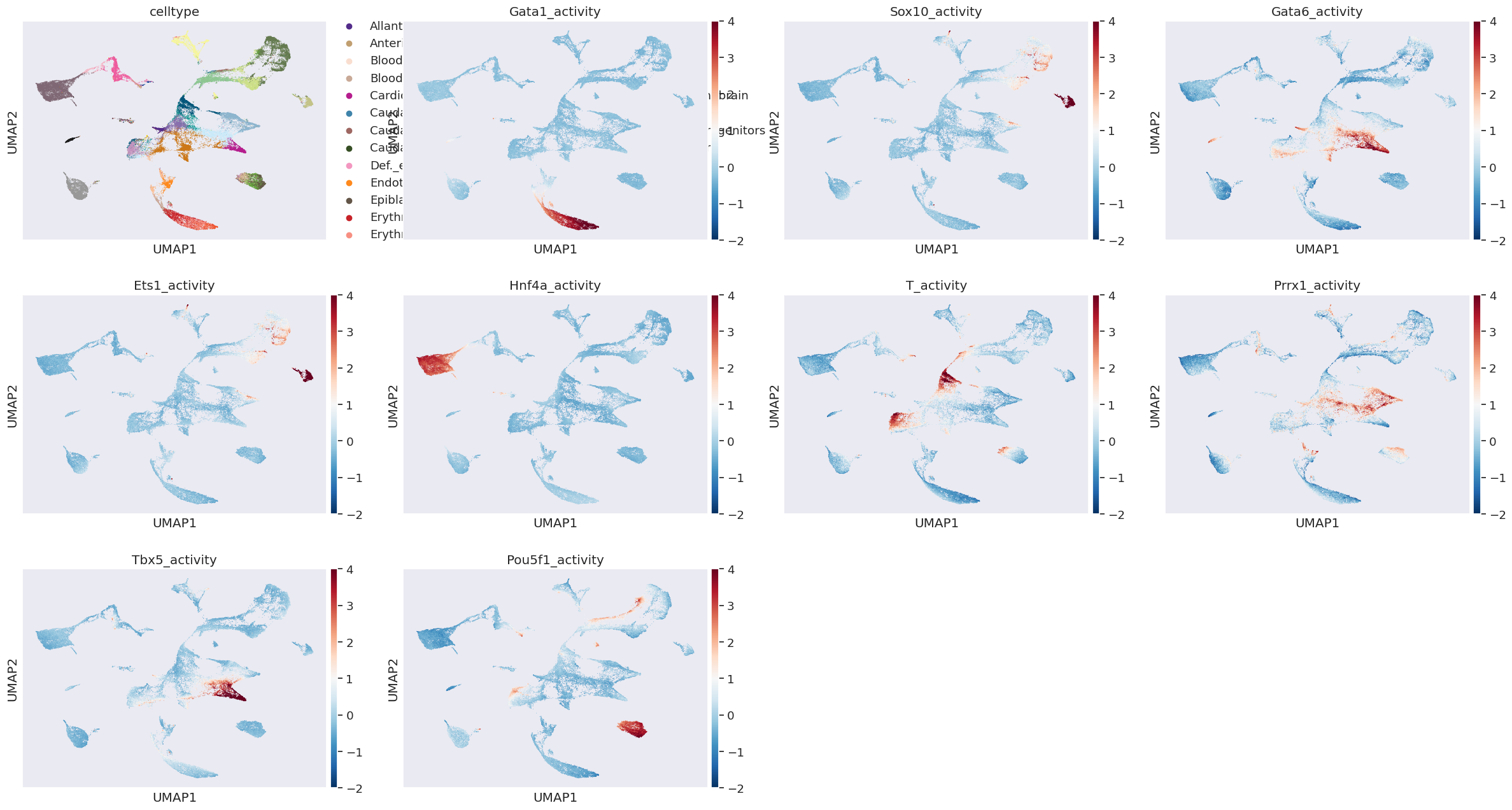
sc.pl.umap(rna_metacell, color = ['celltype','Gata1_activity','Sox10_activity','Gata6_activity','Ets1_activity','Hnf4a_activity','T_activity','Prrx1_activity','Tbx5_activity','Pou5f1_activity'], vmin=-2, vmax=4,cmap='RdBu_r')
22. visualising downstream target genes of a TF#
[83]:
tf_plot="Gata4"
tf_index = list(tf_names).index(tf_plot)
tf_index
[83]:
68
[94]:
df_topic_activator[tf_plot].sort_values(ascending=False)[:5]
[94]:
Topic_3 3.130074
Topic_29 2.430753
Topic_19 1.713511
Topic_39 1.622072
Topic_25 1.532704
Name: Gata4, dtype: float32
since Gata4 is active in multiple topics ( and associated cellltype), we obtain different targets for it in the respective context
[112]:
topic_num = [3,19] # endodermal topics
target_gene_idx = np.where(grn_act[topic_num,tf_index,:].sum(axis=0) >0.0 )[0] # adjust this value to get more stringent/ strongly regulated downstream taregts
genes_endoderm = rna_metacell.var_names[target_gene_idx]
[126]:
genes_endoderm
[126]:
Index(['Abcc2', 'Abcc4', 'Abcc6', 'Ablim1', 'Adcy9', 'Aff2', 'Agbl4', 'Agtr1b',
'Akr1d1', 'Alas1',
...
'Olig1', 'Prdm6', 'Rfx6', 'Snai3', 'Sox17', 'Stat2', 'Stat3', 'Tcf7l2',
'Tead4', 'Zfp523'],
dtype='object', length=387)
[114]:
topic_num = [25] # cardiomyocyte specific topic
target_gene_idx = np.where(grn_act[topic_num,tf_index,:].sum(axis=0) >0.0 )[0]
genes_cardiomyocytes = rna_metacell.var_names[target_gene_idx]
[127]:
genes_cardiomyocytes
[127]:
Index(['Ablim1', 'Acta1', 'Aff2', 'Agbl4', 'Ankrd1', 'Arhgap30', 'Arl4d',
'Bmper', 'Cacna1i', 'Camk2d', 'Casz1', 'Ccdc141', 'Cdh3', 'Cdkn1c',
'Cgnl1', 'Dag1', 'Dsg3', 'Dsp', 'Epb41l3', 'Erich6b', 'Fam151a',
'Frmd4b', 'Ghr', 'Gpx3', 'Grb14', 'Grin2c', 'Grin3a', 'Hcn4', 'Hopx',
'Igf2', 'Il1r1', 'Il1rl1', 'Ins2', 'Kif19a', 'Lama1', 'Lilr4b', 'Lmo7',
'Lrrc43', 'Ly75', 'Meikin', 'Mical2', 'Mmp14', 'Mpz', 'Mttp', 'Myh10',
'Myh6', 'Nebl', 'Nedd4l', 'Nexn', 'Peg3', 'Plac8', 'Popdc2', 'Popdc3',
'Ptk2b', 'Rcan2', 'Rcsd1', 'Rec114', 'Rhoh', 'Rspo1', 'Sipa1l2',
'Slc16a12', 'Slc16a5', 'Smarcd3', 'Svep1', 'Tfpi', 'Tiparp', 'Tln2',
'Tmem202', 'Treml1', 'Trpc6', 'Trpm5', 'Ttc22', 'Unc5b', 'Vav3', 'Dpf3',
'Gata4', 'Prdm6', 'Rfx6'],
dtype='object')
[119]:
# plotting downstream expression of target genes
rna_metacell.X = rna_metacell.layers['counts']
# normalsing raw counts
sc.pp.normalize_total(rna_metacell)
sc.pp.log1p(rna_metacell)
sc.tl.score_genes(rna_metacell,genes_endoderm, score_name="Gata4_endoderm_target")
sc.tl.score_genes(rna_metacell,genes_cardiomyocytes, score_name="Gata4_cardiomyocyte_target")
WARNING: adata.X seems to be already log-transformed.
[139]:
# visualing cell-types on scDoRI computed UMAP
sns.set(font_scale = 1)
sns.set_style("whitegrid")
with plt.rc_context({"figure.figsize": (7, 7), "figure.dpi": (200)}):
sc.pl.umap(rna_metacell, color=["celltype",'Gata4',"Gata4_endoderm_target","Gata4_cardiomyocyte_target"],add_outline=True,outline_color=('white', 'black'),size=10,cmap='RdBu_r',legend_loc=None)
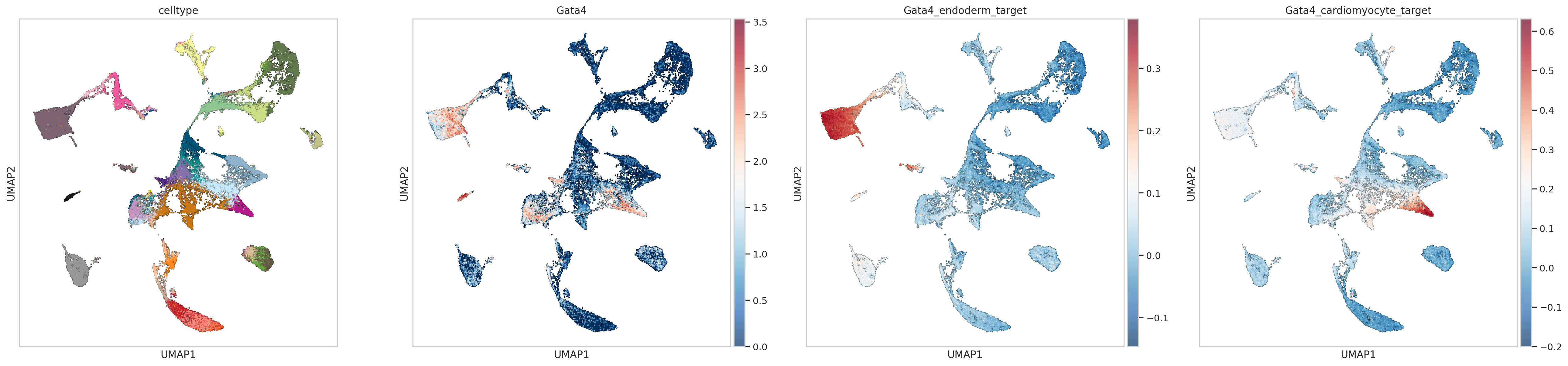
we can clearly see that scDoRI finds differential downstream targets for the same TF in different contexts
we can visualise the TF binding profiles to confirm that these differences are coming from chromatin differences between states
[138]:
#visualsing TF binding scores and topic values where TF is active, on peak umap
sns.set(font_scale = 1)
# topic 3 and 19 are endoderm related and topic 25 is cardiomyocyte specific
with plt.rc_context({"figure.figsize": (3, 3), "figure.dpi": (150)}):
sc.pl.umap(adata_peak, color=['Gata4_activator_binding'] ,cmap='Greens', sort_order=True)
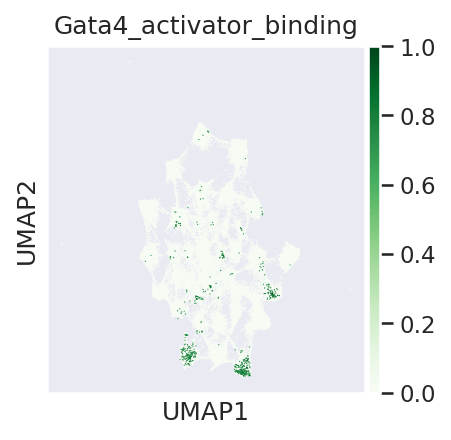
[135]:
#visualsing TF binding scores and topic values where TF is active, on peak umap
sns.set(font_scale = 1)
# topic 3 and 19 are endoderm related and topic 25 is cardiomyocyte specific
with plt.rc_context({"figure.figsize": (3, 3), "figure.dpi": (200)}):
sc.pl.umap(adata_peak, color=['Topic_3','Topic_19','Topic_25'] ,cmap='Greens', vmin=0.8, vmax=1, sort_order=True)
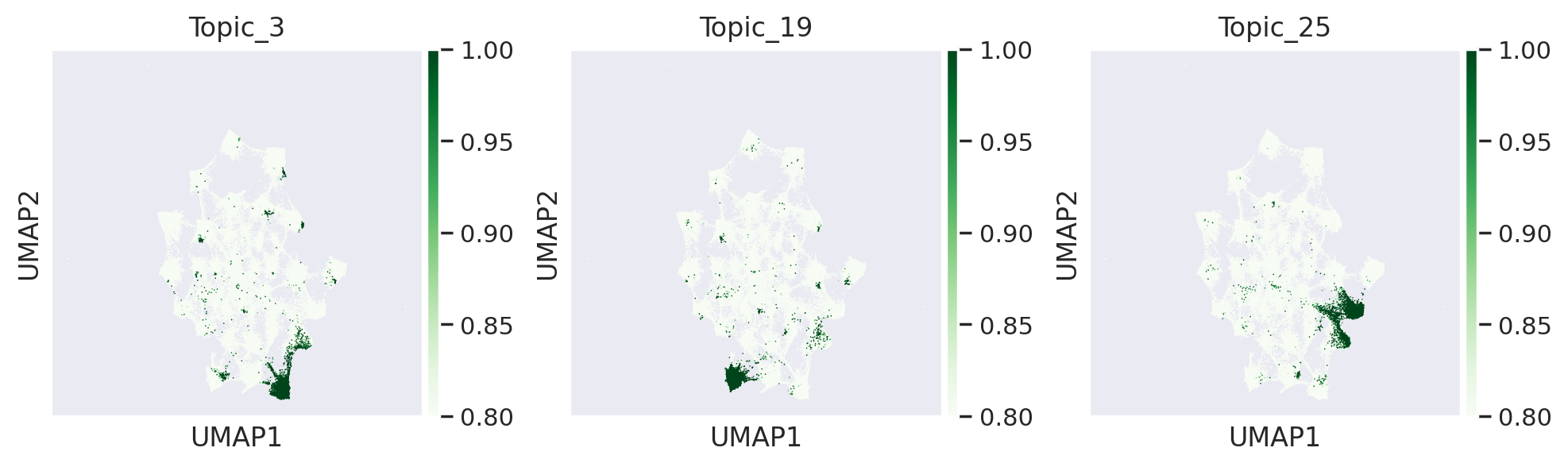
we can see that Gata4 binds to regulatory regions associated with different topics and can regulate different set of genes in those topics respectively
23. Repressor analysis#
[140]:
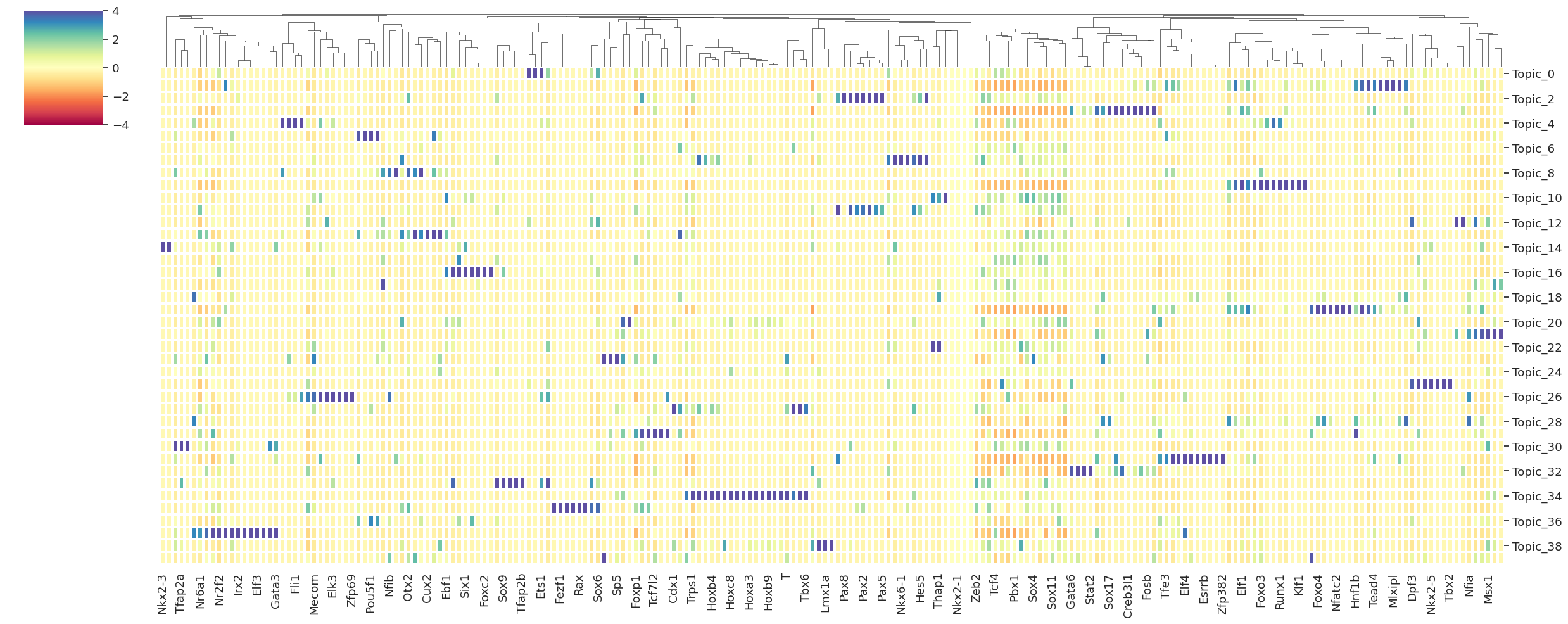
df_topic_repressor, top_regulators_repressor = get_top_repressor_per_topic(
grn_rep,
tf_names,
scdori_latent,
selected_topics=None,
top_k=20,
clamp_value=1e-8,
zscore=True,
figsize=(25, 10),
out_fig=None
)
INFO:scdori.downstream:=== Plotting top repressor regulators per topic ===
INFO:scdori.downstream:=== Done plotting top repressor regulators per topic ===
[141]:
cell_tf_rep = compute_repressor_tf_activity_per_cell(
grn_rep,
tf_names,
scdori_latent,
selected_topics=None,
clamp_value=1e-8,
zscore=True
)
INFO:scdori.downstream:=== Computing TF activity per cell ===
[142]:
df_celltype_tf_rep = pd.DataFrame(cell_tf_rep, columns=tf_names)
df_celltype_tf_rep['celltype'] = rna_metacell.obs['celltype'].values
df_celltype_tf_rep=df_celltype_tf_rep.groupby('celltype').mean()
/tmp/ipykernel_220372/3645810683.py:3: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
df_celltype_tf_rep=df_celltype_tf_rep.groupby('celltype').mean()
24. visualising enhancer gene links#
[353]:
# peaks gene links used by scdori
gene_peak = (model.gene_peak_factor_learnt.detach().cpu().numpy())*(model.gene_peak_factor_fixed.detach().cpu().numpy())
[356]:
gene_peak.shape
[356]:
(4000, 90000)
[ ]:
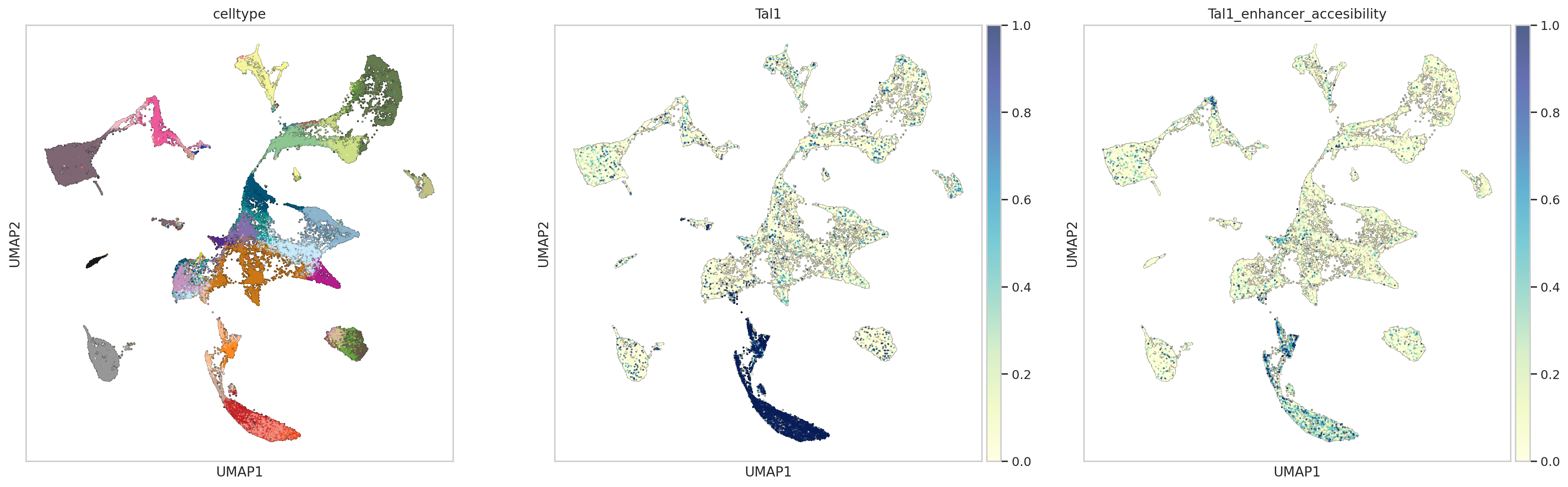
gene_name ="Tal1"
gene_index = list(rna_metacell.var_names).index(gene_name)
enhancers = np.where(gene_peak[gene_index,:] > 0.99)[0] # change this threshold to obtain more links
enhancers = atac_metacell.var_names[enhancers]
plotting accesibility of Tal1 enhancers across celltypes
[425]:
peak_gene_celltype = peak_celltype_df.loc[enhancers]
peak_gene_celltype
[425]:
| Allantois | Anterior_Primitive_Streak | Blood_progenitors_1 | Blood_progenitors_2 | Cardiomyocytes | Caudal_Mesoderm | Caudal_epiblast | Caudal_neurectoderm | Def._endoderm | Endothelium | ... | PGC | Paraxial_mesoderm | Parietal_endoderm | Pharyngeal_mesoderm | Primitive_Streak | Rostral_neurectoderm | Somitic_mesoderm | Spinal_cord | Surface_ectoderm | Visceral_endoderm | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| chr4:115049734-115050334 | -0.471083 | -0.587658 | 2.084388 | 1.262422 | -0.374860 | -0.283599 | -0.426946 | 0.095904 | -0.348895 | 3.098126 | ... | -0.587658 | -0.396268 | -0.571087 | -0.121929 | -0.418987 | -0.408271 | -0.475751 | -0.442686 | -0.477456 | -0.311563 |
| chr4:115071585-115072185 | -0.484199 | -0.387654 | 1.670970 | 1.601316 | -0.436656 | -0.601173 | -0.345486 | -0.710103 | -0.483152 | 3.579220 | ... | -0.710103 | -0.387557 | -0.673809 | -0.424735 | -0.382381 | -0.373902 | -0.579387 | -0.430436 | -0.523610 | -0.559376 |
| chr4:114677387-114677987 | 2.833133 | -0.809878 | -0.706228 | 0.462337 | -0.790806 | 0.652484 | 0.088338 | -0.926896 | 0.048584 | -0.771792 | ... | -0.384917 | -0.183126 | -0.896655 | -0.327314 | -0.495454 | -0.587162 | 0.002362 | -0.556499 | 0.311325 | -0.110331 |
| chr4:115070122-115070722 | -0.418941 | 0.005167 | 1.908539 | 1.283993 | -0.435678 | -0.610410 | -0.464752 | -0.610410 | -0.485386 | 0.334314 | ... | -0.610410 | -0.441879 | -0.496640 | -0.450805 | -0.319608 | -0.264801 | -0.483289 | -0.422015 | -0.483358 | -0.399455 |
4 rows × 37 columns
[426]:
sns.clustermap(peak_celltype_df.loc[enhancers], cmap='RdBu_r', vmin=-5, vmax=5)
[426]:
<seaborn.matrix.ClusterGrid at 0x7f6f66493160>
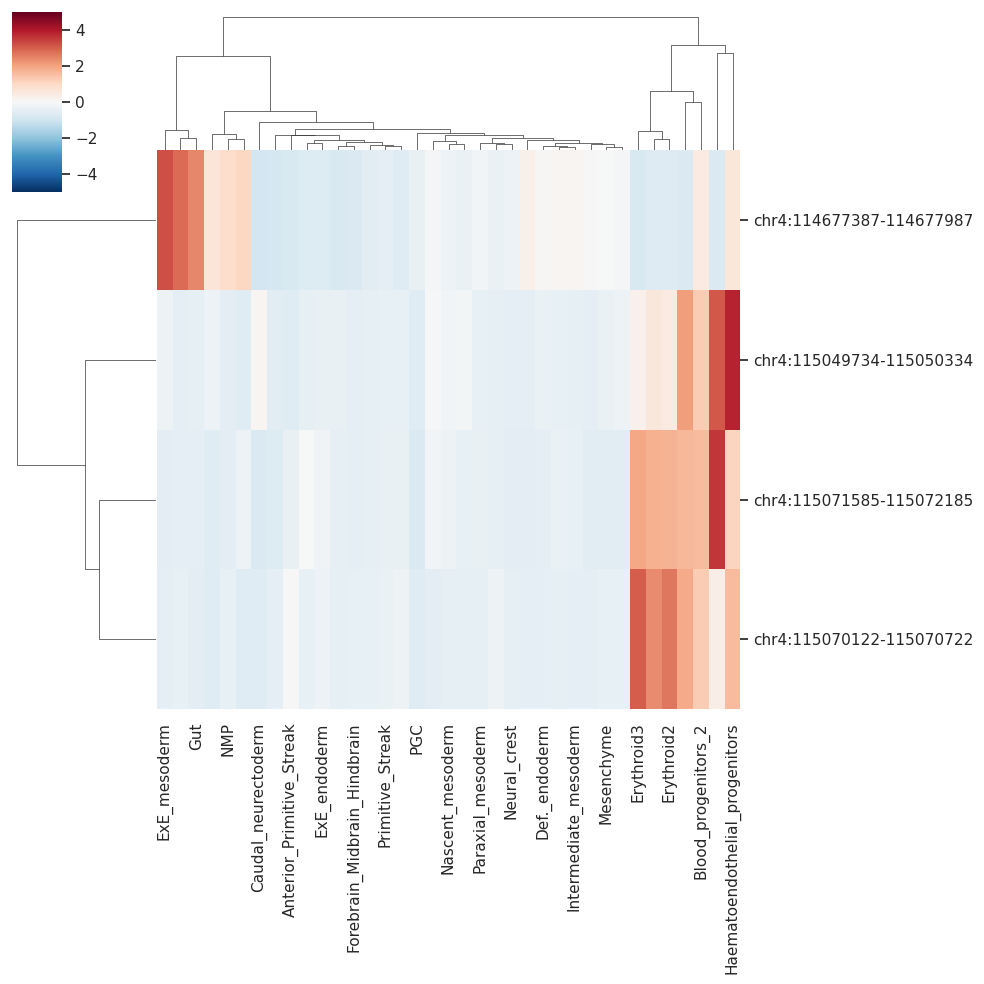
plotting Tal1 expression and net accesibility of its predcited enhancers across celltypes
[410]:
atac_metacell.X = atac_metacell.layers['counts']
# normalsing raw counts
sc.pp.normalize_total(atac_metacell)
sc.tl.score_genes(atac_metacell, enhancers, score_name='Tal1_enhancer_accesibility')
[428]:
rna_metacell.obs['Tal1_enhancer_accesibility'] = atac_metacell.obs['Tal1_enhancer_accesibility'].values
[433]:
sns.set(font_scale = 1)
sns.set_style("whitegrid")
with plt.rc_context({"figure.figsize": (7, 7), "figure.dpi": (200)}):
sc.pl.umap(rna_metacell, color=["celltype",'Tal1',"Tal1_enhancer_accesibility"],add_outline=True,outline_color=('white', 'black'),size=10,cmap='YlGnBu',vmin=0, vmax=1,legend_loc=None)
[ ]: